defget_lps(p, m): lps = [-1] * m k = -1 for i in range(1, m): while k != -1and p[k + 1] != p[i]: k = lps[k] if p[k + 1] == p[i]: k += 1 lps[i] = k return lps
classSolution: defKMPSearch(self, p, s): # 特判 ifnot p: return0 m, n = len(p), len(s) lps = self.get_lps(p, m) j = 0 for i in range(n): while j != 0and s[i] != p[j]: j = lps[j - 1] + 1 if s[i] == p[j]: j += 1 if j == m: # return i - m + 1 print("find at {}".format(i - m + 1)) j = lps[j - 1] + 1 return-1
defget_lps(self, p, m): lps = [-1] * m k = -1 for i in range(1, m): while k != -1and p[i] != p[k + 1]: k = lps[k] if p[i] == p[k + 1]: k += 1 lps[i] = k return lps
defmain(): sol = Solution()
s = "abcruizheuhuruizheaasdasd" p = "ruizhe" res = sol.KMPSearch(p, s) print(res)
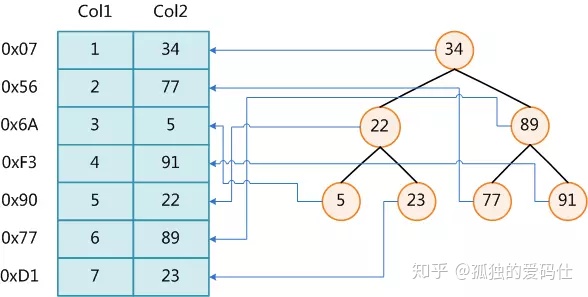
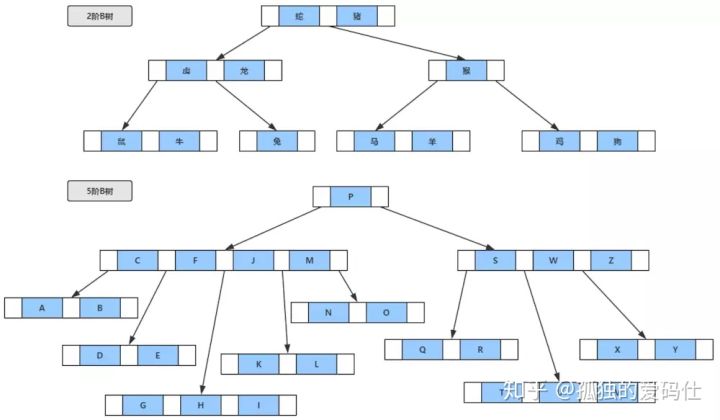
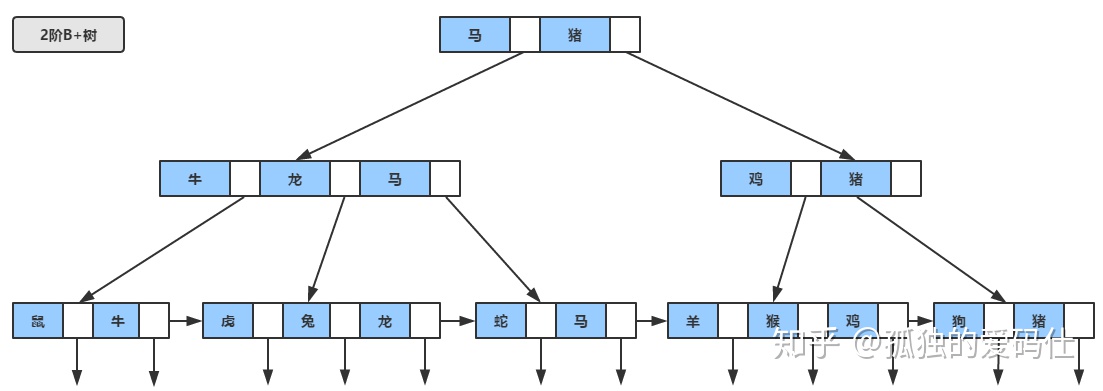
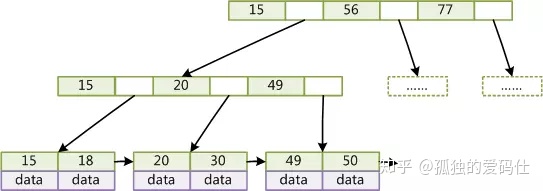
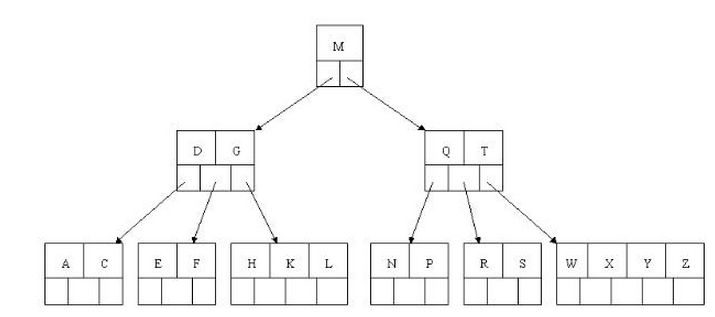
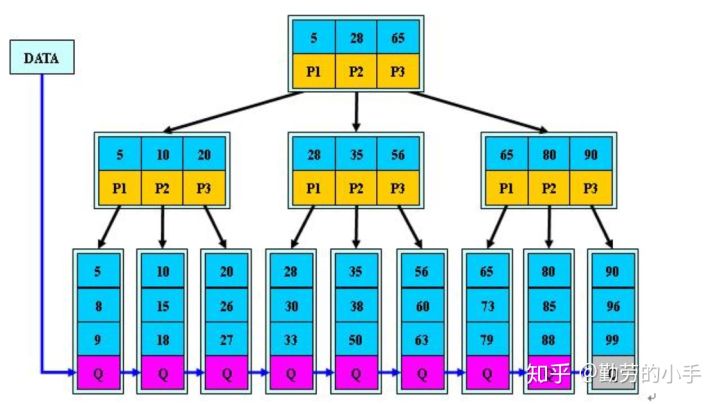
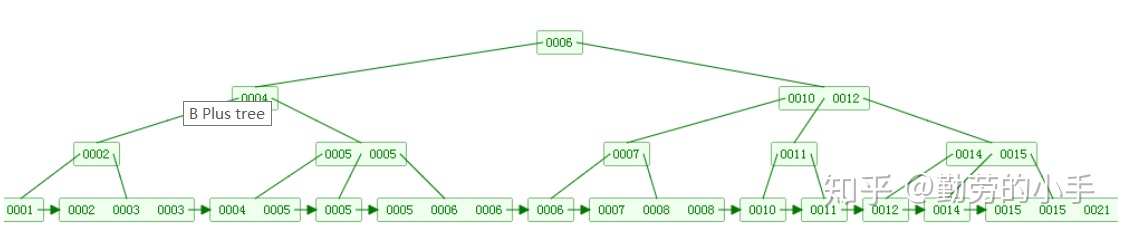
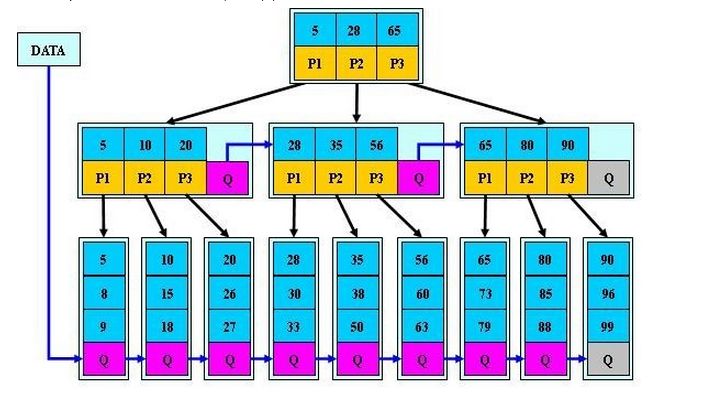
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
classSolution: defgame(self, piles: List[int]) -> int: ifnot piles: return0 n = len(piles) dp = [[[0] * 2for _ in range(n)] for _ in range(n)] for i in range(n): dp[i][i][0] = piles[i] for gap in range(1, n): for i in range(n - gap): j = i + gap left = dp[i + 1][j][1] + piles[i] right = dp[i][j - 1][1] + piles[j] # 先手选左边 if left > right: dp[i][j][0] = left dp[i][j][1] = dp[i + 1][j][0] # 先手选右边 else: dp[i][j][0] = right dp[i][j][1] = dp[i][j - 1][0] return dp[0][n - 1][0] - dp[0][n - 1][1]
defmain(): sol = Solution()
piles = [1, 100, 3] res = sol.game(piles) print(res)
lass Solution: defstoneGame(self, piles: List[int]) -> bool: ifnot piles: returnTrue n = len(piles) dp = [[[0] * 2for _ in range(n)] for _ in range(n)] for i in range(n): dp[i][i][0] = piles[i] for gap in range(1, n): for i in range(n - gap): j = i + gap left = dp[i + 1][j][1] + piles[i] right = dp[i][j - 1][1] + piles[j] # 先手选左边 if left > right: dp[i][j][0] = left dp[i][j][1] = dp[i + 1][j][0] # 先手选右边 else: dp[i][j][0] = right dp[i][j][1] = dp[i][j - 1][0] return bool(dp[0][n - 1][0] - dp[0][n - 1][1])
数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。在两个相邻节点之间传送数据时,数据链路层将网络层交下来的IP数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
Here is a list of few quick examples to show how the algorithm works (you can easily come up with other examples):
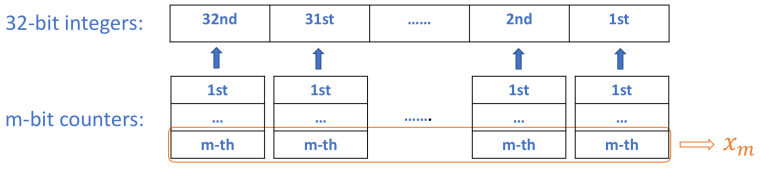
k = 2, p = 1k is 2, then m = 1, we need only one 32-bit integer (x1) as the counter. And 2^m = k so we do not even need a mask! A complete java program will look like:
1 2 3 4 5 6 7 8 9
public int singleNumber(int[] nums) { int x1 = 0; for (int i : nums) { x1 ^= i; } return x1; }
k = 3, p = 1k is 3, then m = 2, we need two 32-bit integers(x2, x1) as the counter. And 2^m > k so we do need a mask. Write k in its binary form: k = '11', then k1 = 1, k2 = 1, so we have mask = ~(x1 & x2). A complete java program will look like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
public int singleNumber(int[] nums) { int x1 = 0, x2 = 0, mask = 0; for (int i : nums) { x2 ^= x1 & i; x1 ^= i; mask = ~(x1 & x2); x2 &= mask; x1 &= mask; }
return x1; // Since p = 1, in binary form p = '01', then p1 = 1, so we should return x1. // If p = 2, in binary form p = '10', then p2 = 1, and we should return x2. // Or alternatively we can simply return (x1 | x2). }
k = 5, p = 3k is 5, then m = 3, we need three 32-bit integers(x3, x2, x1) as the counter. And 2^m > k so we need a mask. Write k in its binary form: k = '101', then k1 = 1, k2 = 0, k3 = 1, so we have mask = ~(x1 & ~x2 & x3). A complete java program will look like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
public int singleNumber(int[] nums) { int x1 = 0, x2 = 0, x3 = 0, mask = 0; for (int i : nums) { x3 ^= x2 & x1 & i; x2 ^= x1 & i; x1 ^= i; mask = ~(x1 & ~x2 & x3); x3 &= mask; x2 &= mask; x1 &= mask; } return x1; // Since p = 3, in binary form p = '011', then p1 = p2 = 1, so we can return either x1 or x2. // If p = 4, in binary form p = '100', only p3 = 1, which implies we can only return x3. // Or alternatively we can simply return (x1 | x2 | x3). }
Lastly I would like to thank those for providing feedbacks to make this post better. Hope it helps and happy coding!
defsample(self, node, k): data = [] # 计数器 counter = 0 while node: counter += 1 # 前k个元素直接放入 if counter <= k: data.append(node) else: # 判断第j个元素是否留下 if random.randint(1, counter) <= k: # 判断替换掉哪个元素 removed_idx = random.randint(0, k - 1) # 替换该元素,放入新元素 data[removed_idx] = node # 如果不留下,就继续 # 访问下一个node node = next(node) return data
defmain(): classListNode(object): def__init__(self, val): self.val = val self.next = None
def__next__(self): return self.next
head = ListNode(0) cur = head for i in range(1, 11): cur.next = ListNode(i) cur = cur.next rs = ReservoirSampling() res = rs.sample(head, 10) for node in res: print(node.val)