def__init__(self): """ Initialize your data structure here. """ self.root = {} self.end_of_word = '#'
definsert(self, word: str) -> None: """ Inserts a word into the trie. """ node = self.root for char in word: node = node.setdefault(char, {}) node[self.end_of_word] = self.end_of_word
defsearch(self, word: str) -> bool: """ Returns if the word is in the trie. """ node = self.root for char in word: if char notin node: returnFalse node = node[char] return self.end_of_word in node
defstartsWith(self, prefix: str) -> bool: """ Returns if there is any word in the trie that starts with the given prefix. """ node = self.root for char in prefix: if char notin node: returnFalse node = node[char] returnTrue
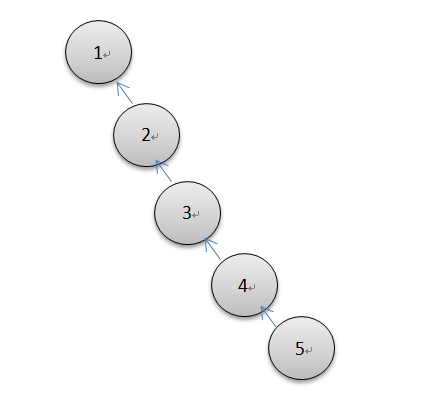
deffind(self, p): """尾递归""" if self.uf[p] < 0: return p self.uf[p] = self.find(self.uf[p]) return self.uf[p]
可以发现这个递归是尾递归,可以改进成循环的方式
1 2 3 4 5 6 7 8
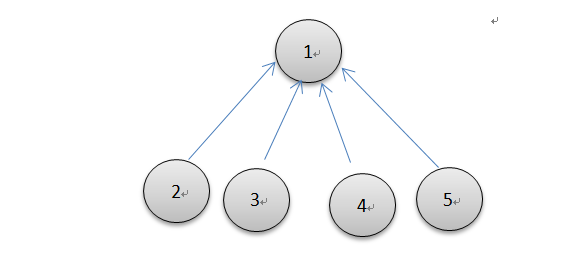
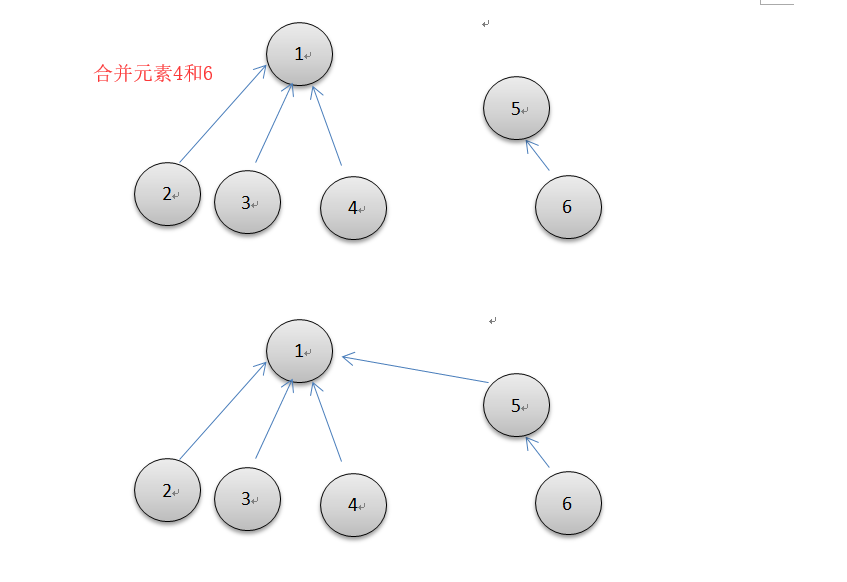
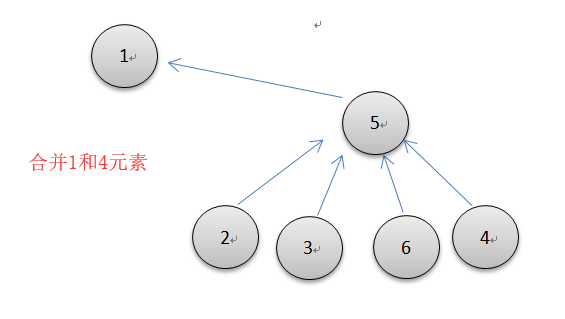
deffind(self, p): """查找p的根节点(祖先)""" r = p # 初始p while self.uf[p] > 0: p = self.uf[p] while r != p: # 路径压缩,把压缩下来的结点祖先全指向根结点 self.uf[r], r = p, self.uf[r] return p
classUnionFind(object): """并查集类""" def__init__(self, n): """长度为n的并查集""" self.uf = [-1for i in range(n + 1)] # 列表0位置空出 self.sets_count = n # 判断并查集里共有几个集合, 初始化默认互相独立
# def find(self, p): # """查找p的根结点(祖先)""" # r = p # 初始p # while self.uf[p] > 0: # p = self.uf[p] # while r != p: # 路径压缩, 把搜索下来的结点祖先全指向根结点 # self.uf[r], r = p, self.uf[r] # return p
# def find(self, p): # while self.uf[p] >= 0: # p = self.uf[p] # return p
deffind(self, p): """尾递归""" if self.uf[p] < 0: return p self.uf[p] = self.find(self.uf[p]) return self.uf[p]