确保Web安全的HTTPS
HTTP主要有这些不足,列举如下:
通信使用明文(不加密),内容可能会被窃听
不验证通信方的身份,因此有可能遭遇伪装
无法证明报文的完整性,所以有可能已遭篡改
这些问题不仅在HTTP上出现,其他未加密的协议中也会存在这类问题。
除此之外,HTTP本身还有很多缺点。而且,还有像某些特定的Web服务器和特定的Web浏览器在实际应用中存在的不足(也可以说成是脆弱性或安全漏洞),另外,用Java和PHP等变成语言开发的Web应用也可能存在安全漏洞。
Python实现重试机制
1 | # retry_decorator.py |
Python函数参数默认值的陷阱和原理深究
参考
http://cenalulu.github.io/python/default-mutable-arguments/
本文将介绍使用mutable对象作为Python函数参数默认值潜在的危害,以及其实现原理和设计目的
陷阱重现
我们用实际的例子演示一下我们今天所要讨论的主要内容。下面一段代码定义了一个名为generate_new_list_with的函数。该函数的本意是在每次都调用时都新建一个包含有给定element值的list。而实际运行结果如下:
1 | def generate_new_list_with(my_list=[], element=None): |
可见代码运行结果并不和我们预期的一样。list_2在函数的第二次调用时并没有得到一个新的list并填入2,而是在第一次调用结果的基础上append了一个2。为什么会发生这样在其他编程语言中简直像bug一样的问题呢?
准备知识:Python变量的实质
要了解这个问题的原因我们现需要一个准备知识,那就是:Python变量到底是如何实现的?Python变量区别与其他编程语言的声明&赋值方式,采用的是创建&指向的类似于指针的方式实现的。即Python中的变量实际上是对值或者对象的一个指针(简单的说他们是指的一个名字)。我们来看一个例子。
1 | p = 1 |
对于传统语言,上面这段代码的执行方式将会是,现在内存中声明得到一个p的变量,然后将1存入变量p所在内存。执行家法操作的时候得到2的结果,将2这个数值再次存入到p所在内存地址中。可见整个执行活成中,变化的是变量p所在内存地址上的值。
上面这段代码中,Python实际上是现在执行内存中创建了一个1的对象,并将p指向了它。在执行加法操作的时候,实际上通过加法操作得到了一个2的新对象,并将p指向这个新的对象。可见整个执行过程中,变化的是p指向的内存地址。
函数参数默认值陷阱的根本原因
一句话来解释:Python函数的参数默认值,是在编译阶段就绑定的。
现在,我们先从一段摘录来详细分析这个陷阱的原因。下面是一段从Python Common Gotchas中摘录的原因解释:
Python's default arguments are evaluated once when the function is defined, not each time the function is called(like it is in say, Ruby). This means that if you use a mutable default argument and mutate it, you will and have mutated that object for all future calls to the function as well.
可见如果参数默认值是在函数编译compile阶段就已经被确定。之后所有的函数调用时,如果参数不显示的给予赋值,那么所谓的参数默认值不过是一个指向那个在compile阶段就已经存在的对象的指针。如果调用函数时,没有显示指定传入参数值的话。那么所有这种情况下的该参数都会作为编译时创建的那个对象的一种别名存在。如果参数的默认值是一个不可变(Immutable)数值,那么在函数体内如果修改了该参数,那么参数就会重新指向另一个新的不可变值,而如果参数默认值是和本文最开始的举例一样,是一个可变对象(Mutable),那么情况就比较糟糕了。所有函数体内对于该参数的修改,实际上都是对compile阶段就已经确定的那个对象的修改。对于这么一个陷阱在Python官方文档中也有特别提示:
Important warning: The default value is evaluated only once. This makes a difference when the default is a mutable object such as a list, dictionary, or instances of most classes.
如何避免这个陷阱带来不必要麻烦
当然最好的方式是不要使用可变对象作为函数默认值。如果非要这么用的话,下面是一种解决方案。还是以文章开头的需求为例:
1 | def generate_new_list_with(my_list=None, element=None): |
为什么Python要这么设计
这个问题的答案在 STackOverFlow上可以找到答案。这里将得票数最多的答案最重要的部分摘录如下:
Actually, this is not a design flaw, and it is not because of internals, or performance. It comes simply from the fact that functions in Python are first-class objects, and not only a piece of code. As soon as you get to think into this way, then it completely makes sense: a function is an object being evaluated on its definition; default parameters are kind of "member data" and therefore their state may change from one call to the other - exactly as in any other object. In any case, Effbot has a very nice explanation of the reasons for this behavior in Default Parameter Values in Python. I found is very clear, and I really suggest reading it for a better knowledge og how function objects work.
在这个回答中,答者认为是出于Python编译器的实现方式考虑,函数是一个内部一级对象。而参数默认值是这个对象的属性。在其他任何语言中,对象属性都是在对象创建时做绑定的。因此,函数参数默认值是在编译时绑定就不足为奇了。然而,也有很多一些回答者不买账,认为即使是first-class object也可以使用closure的方式在执行绑定。
This is not a design flaw. It is a design decision; perhaps a bad one, but not an accident. The state thing is just like any other closure: a closure is not a function, and a function with mutable default argument is not a function.
甚至还有反驳这抛开实现逻辑,单纯从设计角度认为:只要有违背程序员基本思考逻辑的行为,都是设计缺陷。
加油武汉!
设计模式--函数编程中的装饰者模式
假设我们想对一个函数进行它执行时间的打印,我们可以用函数式编程,完成一个装饰器。
下面给出Python3和Go中的代码:
1 | def timeSpent(func): |
1 | func timeSpent(inner func(op int) int) func(op int) int { |
这样就可以对一个想要计算执行时间的函数,快速添加计算执行时间的代码。
转:稻盛和夫《活法》读书笔记
稻盛和夫《活法》读书笔记
稻盛和夫《活法》,是讲我们该如何工作和生活。我们将以什么样的态度、方法去看问题、做事情。
1、人生的意义是什么?
人生的价值和意义是提升心性、磨炼灵魂。我们经历的悲欢离合,都是在磨练我们的灵魂。为了让我们在死去的时候,灵魂比刚出生时更加纯洁。
我想,每个人对人生的意义理解不一样,人为什么活着?
活着,为了实现心中的理想。这个理想,可能是爱,想让家人过得更好。也有可能是自我价值的实现,能给他人带来价值,从而实现自己的价值。或者去尽可能多地去体验生活,去感受人生的不同。
如果人生的意义是磨练灵魂,那我们在看待成败得失时,内心就会更加平静,尤其是在我们遇到低谷、逆境时,我们知道那是老天爷来考验我们,为的是让我们在人生逆境之中,磨练我们脆弱的心,增强我们的抗压能力,激发我们的潜能。如果我们的人生都是一帆风顺,自然也体会不到平淡的生活才是幸福。经历了高低起伏,便丰富了我们对人生的看法。
2、怎么提升人格?
精进:拼命努力、心无旁骛、埋头眼前的工作。精进是提高人性、磨练人格最重要的,最有效的方法。稻盛和夫先生是提倡专心致志的工作,忘我的工作。他说劳动具有克制欲望、磨练心志、塑造人格的功效。
想一想这个事情竟然这么简单,全身心投入工作就可以带来这么多好处,如果对工作心不在焉、马马虎虎,那我们也不可能有好的结果。
3、怎样才能使人生更美好、更幸福?
人生和工作的结果=思维方式热情能力
能力:才能、智商
热情:干劲,努力程度
思维方式:心态、思想(有正负之分)
如果一个人的能力90分,但他的热情只有30分,热情*能力最后得分2700分。
如果一个人的能力60分,但他的热情有90分,热情*能力最后得分5400分。
思维方式不变的情况下,一个能力一般,但却愿意付出很高热情的人,拿到的结果超过那些自恃聪明,却不愿意付出的人。
所以作为能力平平的人,更应该投入更多的热情,往正确的思维方式上行动。你只能努力奔跑,才可能留在原地。
4、“心想事成”是成功最简单的法则。
只有主动追求的东西才能到手,“心不唤物,物不至”。要将不可能变为可能,首先需要达到“痴狂”程度的强烈愿望,坚信目标一定能实现并付出不懈的努力,朝着目标奋勇前进。不管是人生还是经营,这才是达到目的的唯一方法。
心想事成,不是心里想想,事情就成功了。想的要足够频繁,时时想,常常想,想到你睡觉做梦都在想。想得要有深度,不断剖析,从表现现象找出事物的本质。
李笑来有提到过中国的一个有钱人,刘益谦。他是实业家,收藏家,资产在300亿以上。
有人问刘益谦:你为什么比我有钱?
刘益谦想了想,很认真的问道:你想不想赚钱呢?
对方说:我当然想啊!
刘益谦说:那你每天花多长时间想赚钱呢?我每天都在想怎么赚钱,我每时每刻都在想,我早上起来在想,我坐在马桶上在想,你呢,你就是偶尔想想,然后去干别的了,想别的了。咱们在这件事上花的时间不一样,那怎么可能一样有钱呢?
5、“喜欢”燃起热情
物质有三种类型:
1、点火就能燃烧的可燃性物质;
2、点火也燃烧不起来的不燃性物质;
3、靠自己就能燃烧的自燃性物质。
人的类型也一样,有的人没有任何周围的督促,他自己就能熊熊燃烧。但还有一种人很冷漠,或者很麻木,即使给他能量他也绝不燃烧,属于不燃型的人。这种人往往有能力却缺乏激情,以致将自己的能力埋没。作为组织,不喜欢不燃烧的人,因为他们自己冷若冰霜不说,有时还会夺走周围人的热量。能做成事情的人,他们不仅自我燃烧,而且其能量还可与周围人分享。
怎样才能成为自燃型的人?
最好最有效的办法就是“喜欢自己的工作”。喜欢自己的工作,你就要全身心投入到工作中,投入你的激情、时间、智慧、能力,想尽一切办法去完成自己的工作。当你收获到了工作上带来的回报,你就会更加努力地投入工作,如此,这样正循环。
鲁迅语录
- 他们这群人,又想吃人,又是鬼鬼祟祟,想法子遮掩,不敢直截下手,真要令我笑死。我忍不住,便放声大笑起来,十分快活。自己晓得这笑声里面,有的是义勇和正气。 --鲁迅《狂人日记》
- 人类的悲欢并不相通,我只是觉得他们吵闹。——鲁迅《而已集·小杂感》
- 无穷的远方,无数的人们,都和我有关。——鲁迅《且介亭杂文末集·这也是生活》
江湖再见
普通索引和唯一索引的选择
MySQL中尽量使用普通索引,减少使用唯一索引
查询过程
平均性能差异微乎其微。
更新过程
change buffer
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InnoDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
需要说明的是,虽然名字叫change buffer,实际上它是可以持久化的数据。也就是说,change buffer在内存中有拷贝,也会下被写入到磁盘上。
将change buffer中的操作应用到原数据页,得到最新结果的过程称为merge。除了访问这个数据页会触发merge外,系统有后台线程会定期merge。在数据库正常关闭的(shutdown)的过程中,也会执行merge操作。
显然,如果能够将更新操作先记录在change buffer,减少读磁盘,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用buffer pool的,所以这种方式还能后避免占用内存,提高内存利用率。
那么,什么条件下可以使用change buffer呢?
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束。比如,要插入(4,400)这个记录,就要先判断现在表中是否已经存在k=4的记录,而这必须要将数据页读入内存才能判断。如果都已经读入到内存了,那直接更新内存会更快,就没必要使用change buffer了。
因此,唯一索引的更新就不能使用change buffer,实际上也只有普通索引可以使用。
change buffer用的是buffer pool里的内存,因此不能无限增大。change buffer的大小,可以通过参数innodb_change_buffer_max_size来动态设置。这个参数设置为50的时候,表示change buffer的大小最多只能占用buffer pool的50%。
现在,你已经理解了change buffer的机制,那么我们再一起来看看如果要在这张表中插入一个新纪录(4,400)的话,InnoDB的处理流程是怎样的。
第一种情况是,这个记录要更新的目标页在内存中。那么两者差不多。
第二种情况是,这个记录要更新的目标页不在内存中。那么唯一索引要读入内存,涉及磁盘随机IO的访问,是成本最高的操作之一。
change buffer的使用场景
普通索引的所有场景,使用change buffer都可以起到加速作用吗?
因为merge的时候是真正进行数据更新的时刻,而change buffer记录的变更越多(也就是这个页面上要更新的次数越多),收益就越大。
因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好。这种业务模型常见的就是账单类、日志类的系统。(这类写入比较多的业务类型可以使用LSM树作为数据结构的数据库)。
反过来,假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在change buffer,但之后由于马上要访问这个数据页,会立即触发merge过程。这样随机访问IO的次数不会减少,反而增加了change buffer的维护代价。
索引该如何选择和实践呢?
普通索引和唯一索引应该如何选择。查询能力上没差别,主要考虑的是对更新性能的影响。所以,我建议你尽量选择普通索引。
如果所有的更新后面,都马上伴随着对这个记录的查询,那么你应该关闭change buffer。而在其他情况下,change buffer都能提升更新性能。
在实际应用中,你会发现,普通索引和change buffer的配合使用,对于数据量大的表的更新优化还是很明显的。
特别的,在使用机械硬盘时,change buffer这个机制的收效是非常显著的。所以,当你有一个类似”历史数据“的库,并且处于成本考虑用的是机械硬盘时,那你应该特别关注这些表里的索引,尽量使用普通索引,然后把change buffer尽量开大,以确保这个”历史数据“表的数据写入速度。
change buffer和redo log
现在,我们要在表上执行这个语句:
1 | mysql> insert into t(id, k) values(id1, k1), (id2, k2); |
这里,我们假设当前k索引树的状态,查找到位置后,k1所在的数据页在内存(InnoDB buffer pool)中,k2所在的数据页不在内存中。如果2所示是带change buffer的更新状态图。
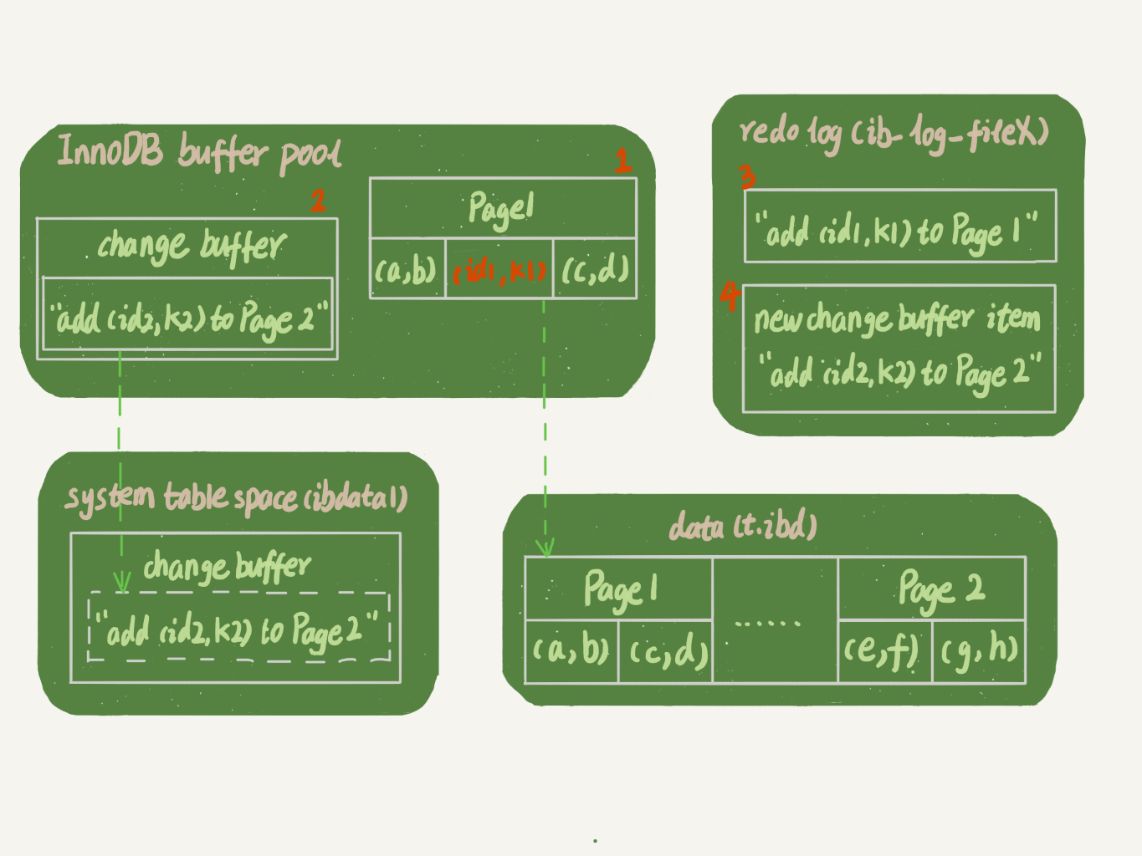
分析这条更新语句,你会发现它涉及了四个部分:内存、redo log(ib_log_fileX)、数据表空间(t.ibd)、系统表空间(ibdata1)。
这条更新语句做了如下的操作(按照图中的数组顺序):
- Page 1在内存中,直接更新内存;
- Page 2没有在内存中,就在内存的change buffer区域,记录下”我要往Page2插入一行“这个信息
- 将上述两个动作记录到redo log中。
做完上面这些,事务就可以完成了。所以,你会看到,执行这条更新语句的成本很低,就是写了两处内存,然后写了一处磁盘(两次操作合在一起写了一次磁盘),而且还是顺序写的。
同时,图中的两个虚线箭头,是后台操作,不影响更新的响应时间。
那么这之后的读请求,要怎么处理呢?
比如,我们现在要执行select * from t where k in (k1, k2)。这里,我画了这两个请求的流程图。
如果读语句发生在更新语句后不久,内存中的数据都还在,那么此时的这两个读操作就与系统表空间(ibdata1)和redo log(ib_log_fileX)无关了。
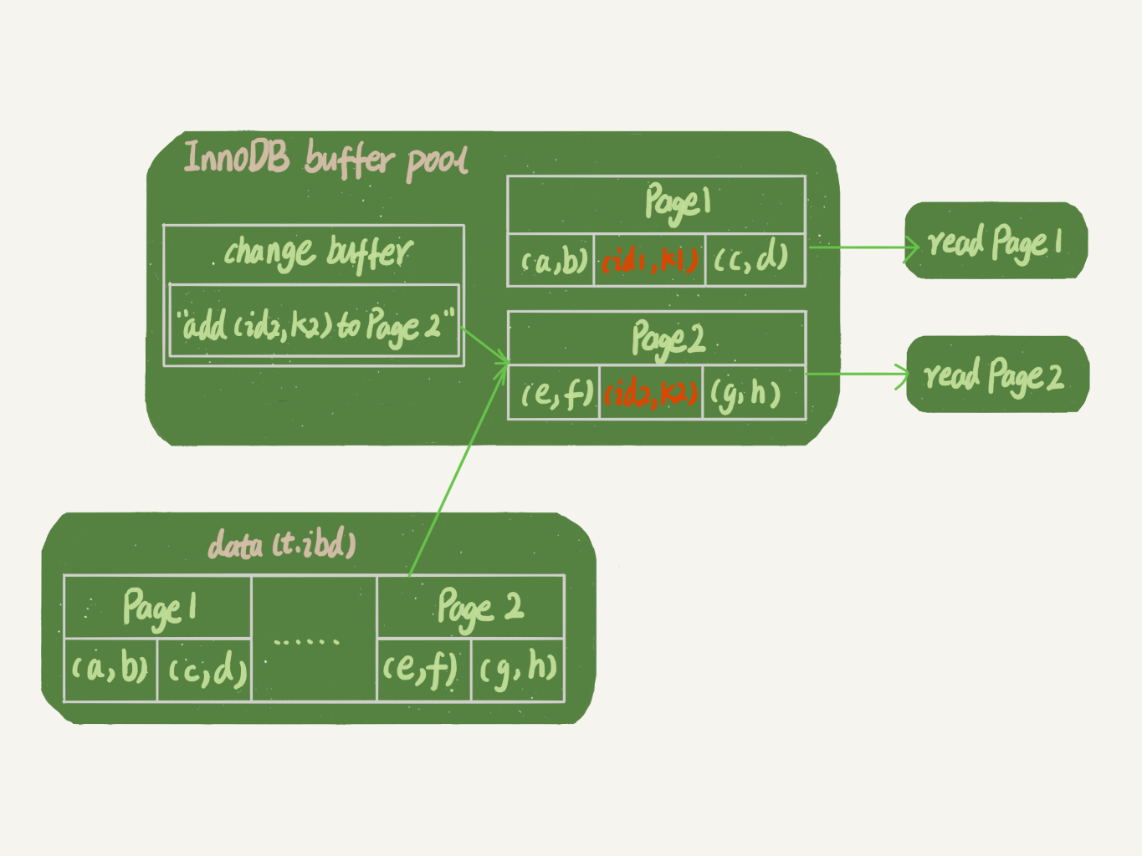
图中可以看到:
- 读Page1的时候,直接从内存返回。有同学之前问到,WAL之后读数据,是不是一定要读盘,是不是一定要从redo log里面把数据更新以后才可以返回?其实是不用的。你可以看一下图3的状态,虽然磁盘上还是之前的数据,但是这里直接从内存返回结果,结果是正确的。
- 要读Page 2的时候,需要把Page 2从磁盘读入内存中,然后应用change buffer里面的操作日志,生成一个正确的版本并返回结果。
可以看到,直到需要读Page 2的时候,这个数据页才会被读入内存。
wal机制可以将数据按顺序写到redo log(减少随机写对io的消耗)对普通索引上的数据进行修改,通常是将修改动作记录到change buffer(减少随机读磁盘的消耗),待查询时如果数据页不在内存,先读取到内存,再将change buffer中的修改动作通过merge操作,合并数据。
- 如果业务要求有唯一键。业务正确性优先,文章的前提是业务代码已经保证不会写入重复数据,在这情况下,讨论性能问题。如果业务不能保证,或者业务就是要求数据库来做约束,那么没得选,必须创建唯一索引。这种下,如果碰上了大量插入数据慢、内存命中率低的时候,可以给你多提供一个排查思路。
- 然后,在一些“归档库”的场景,你是可以考虑使用普通索引的。比如,线上数据只需要保留半年,然后历史数据保存在归档库。这时候,归档数据已经是确保没有唯一键冲突了。要提高归档效率,可以考虑把表里面的唯一索引改成普通索引。