向所有在为弱势群体发声、为众人谋幸福的人们致敬。
如何管理跨代理服务器的长短连接
HTTP的请求可以在长连接和短连接上执行。这篇文章介绍长连接和短连接的区别,以及如果客户端和源服务器之间有多个代理服务器,那么这些代理服务器会如何处理长连接。
在我们谈HTTP的长连接和短连接的差别之前呢,我们先来看一下之前介绍过的HTTP连接的常见的一个流程。
HTTP连接的常见流程
http://www.joes-hardware.com:80/power-tools.html
- 浏览器解析出主机名 www.joes-headware.com
- 浏览器查询这个主机名的IP地址(DNS)202.43.78.3
- 浏览器获得端口号(80)
- 浏览器发起到202.43.78.3端口80的连接(TCP)
- 浏览器向服务器发送一条HTTP GET报文(服务器必须在这个连接上立刻的返回一个响应,而不能去插播其他的响应)
- 浏览器从服务器读取HTTP响应报文
- 浏览器关闭连接
这就是一个完整的请求的过程,也是一个短连接的流程。
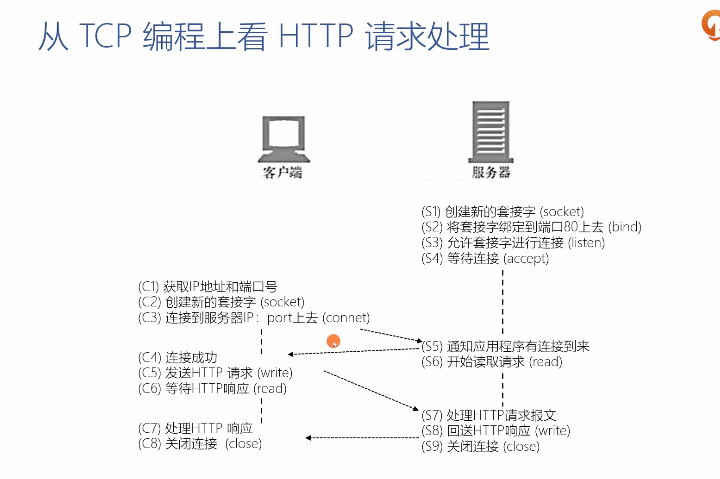
从TCP编程上看HTTP请求处理
服务器:
- 创建新的套接字(socket)
- 将套接字绑定到端口80上去(bind)
- 允许套接字进行连接(listen)
- 等待连接(accept)
- 通知应用程序有连接到来
- 开始读取请求(read)
- 处理HTTP请求报文
- 回送HTTP响应(write)
- 关闭连接(close)
客户端:
- 获取IP地址和端口号
- 创建新的套接字(socket)
- 连接到服务器IP:port上去(connect)
- 连接成功
- 发送HTTP请求(write)
- 等待HTTP响应(read)
- 处理HTTP响应
- 关闭连接(close)
短连接与长连接
我们先谈一个事务的概念,我们假定一个事务就是一个请求对应着一个响应。那么什么是短连接呢?就是从时间线上来看,每建立一个连接1,处理一个请求,得到一个响应以后,这个连接就关闭,然后处理事务2的时候,又发起请求2和响应2,连接2也接着关闭,那么这就是一个串行的一个短连接。什么叫长连接呢?现在客户端与服务器建立了一个连接,执行完第一个事务以后,我们又来执行第2个事务、第3个事务、第4个事务,一直执行在同一个连接上,那么这就叫做持久的长连接。长连接是由什么来决定的呢?因为并不是所有的浏览器和客户端都支持长连接,特别是现在有一些非常古老的服务器,是不支持长连接的,那么客户端和服务器需要去沟通,那么沟通是通过什么呢?就通过Connection这样一个头部。Connection头部如果添加了Keep-Alive这样的一个值的时候,就表示长连接的一个意思。如果是请求中携带了Connection: Keep-Alive表示客户端说我希望使用长连接,如果服务器端也支持场链接的话,它会回的响应中也添加Connection: Keep-Alive。那么接下来,我们就可以复用这个长连接,去发送请求了。
- Connection头部
- Keep-Alive:长连接
- 客户端请求长连接
- Connection:Keep-Alive
- 服务器表示支持长连接
- Connection:Keep-Alive
- 客户端复用连接
- HTTP/1.1默认支持长连接
- Connection: Keep-Alive无意义(所以传递它意义并不大)
- 客户端请求长连接
- Close:短连接(如果我们明确地表示不支持长连接呢?特别是在HTTP/1.1中呢,我们可以加Connection:Close。就表示这将是一个短连接。
- (那么Connection除了表示长连接和短连接以外呢,它还有一个功能,就是对于Connection后面列出的头部,它表示的含义是对代理服务器有一些要求,就是代理服务器在转发这个请求的时候,请不要去转发我Connection中列出的头部)对代理服务器的要求
- 不转发Connection列出头部,该头部仅与当前连接相关(比如说Connection里面列出了一个Cookie,那么代理服务器转发给源服务器的时候就需要把Cookie这个头部给它去除掉)
- Keep-Alive:长连接
Connection仅针对当前连接有效
Connection如果中间有代理服务器的时候,其实Connection并不是表示对完整的一个链路上都要使用长连接,而它仅表示是对当前的TCP连接,也就是说我们客户端与代理服务器之间这条连接是使用长连接。客户端中Connection: Keep-Alive只是表示与第一个代理服务器之间使用长连接,代理服务器可能和反向代理服务器呢,是不想使用长连接的,比如说这个代理服务器是一个比较老的版本,直接发了一个Connection: Close。表示我与这个代理服务器不想使用长连接,而这个反向代理服务器和我们企业内网的比如说源服务器之间,都支持长连接,那么这个代理服务器发出一个Connection:Keep-Alive,而源服务器跟这个反向代理服务器告诉说Connection:Keep-Alive,那么它们俩之间就是用这个长连接了。而这个反向代理服务器和这个正向代理服务器之间呢,使用的就是短连接,而这个正向代理服务器,因为它不支持长连接,所以它告诉客户端说,虽然你跟我说需要使用Keep-Alive,但是我是不支持的,所以我返回了一个Connection:Close。
这个场景中,主要是第一个正向代理服务器不支持长连接,但是它有一个优点,虽然我不支持,但是我认得Connection这个头部,我知道客户端说Keep-Alive时表示它想使用长连接,而接下来我不支持长连接,那么我给我的下游会传一个Connection: Close。如果这个代理服务器是一个非常古老的代理服务器,也就是我们Internet规模下确实存在可能非常古老的这样的代理服务器的场景,那么它其实是不认得Connection这个头部的,因为我们只有在HTTP/1.1协议中才引入了这个Connection头部,所以在它不认识的情况下呢,它会把它的Connection:Keep-Alive原封不动的传到上游去。当然它也不可能支持长连接。
代理服务器对长连接的支持
- 问题:各方间错误使用了长连接
- 客户端发起长连接
- 代理服务器陈旧,不能正确的处理请求的Connection头部,将客户端请求中的Connection:Keep-Alive原样转发给上游服务器
- 上游服务器正确的处理了Connection头部,在发送响应后没有关闭连接,而试图保持、复用与不认长连接的代理服务器的连接
- 代理服务器收到响应中Connection: Keep-Alive后不认,转发给客户端,同时等待服务器关闭短连接
- 客户端收到了Connection:Keep-Alive,认为可以复用长连接,继续在该连接上发起请求
- 代理服务器出错,因为短连接上不能发起两次请求
- Proxy-Connection
- 陈旧的代理服务器不识别该头部:退化为短连接
- 新版本的代理服务器理解该头部
- 与客户端建立长连接
- 与服务器使用Connection替代Proxy_connection头部
小结
这篇文章介绍HTTP中的keep-alive长连接,长连接可以有效的减少TCP的握手次数,也在拥塞控制上能够提升我们的吞吐量,我们也介绍了如果在网络中,存在非常古老的代理服务器,是需要我们通过Proxy-Connection头部,来替换Connection头部,来完成长连接的处理。
参考
陶辉老师Web协议详解与抓包实战https://time.geekbang.org/course/detail/100026801-94635
HTTP的错误响应码(For Reference)
将介绍400、500系列表示错误的响应码,搞清楚这些错误响应码的含义对于我们快速地定位问题非常有帮助。
- 4xx:客户端出现错误
- 400 Bad Request:服务器认为客户端出现了错误,但不能明确判断为以下哪种错误时使用此错误码。例如HTTP请求格式错误。
- 401 Unauthorized:用户认证信息缺失或者不正确,导致服务器无法处理请求。(比如URI如果需要传递user和password的时候,往往会得到401Unauthorized)
- 407 Proxy Authentication Required:(对401的补充,401往往是源服务器返回的用户信息验证不通过,如果代理服务器会首先验证用户的认证信息的话,那么代理服务器没有通过就会返回407。比如将常在机场、网吧等场合下,如果我们信息验证没通过,可能就会收到407)对需要经由代理的请求,认证信息未通过代理服务器的验证
- 403 Forbidden:服务器理解请求的含义,但没有权限执行此请求(常见于搭建了一个服务器,但是我对于某个目录下的文件访问可能没有权限,这个时候客户端就会收到403 Forbidden)
- 404 Not Found:服务器没有找到对应的资源(对应的资源已经丢失的)
- 410 Gone:(对404 Not Found的一个补充,404只是说服务器找不到对应的资源,但是不知道过一会是不是就能再次找到)服务器没有找到对应的资源,且明确的知道该位置永久性找不到该资源。(很少使用到,实际情况中比较难以遇到)
- 405 Method Not Allowed:服务器不支持请求行中的method方法(比如trace方法在nginx 0.5版本中已经明确的不支持了,现在访问任何一个这样的服务器使用trace方法都会得到405 method not allowed)
- 406 Not Acceptable:对客户端指定的资源表述不存在(例如对语言或者编码有要求),服务器返回表述列表共客户端选择。
- 408 Request Timeout:服务器接收请求超时(比如说服务器接收一个请求最长只能用一分钟,但是一分钟还没有发完我们的请求,就用可能发声这样的事情)
- 409 Conflict:(post或者put上传一个文件,但是目标位置已经存在了版本更新的一个资源,我们这个资源没有办法去覆盖它,这时候就会拿到409 Conflict)资源冲突,例如上传文件时目标位置已经存在版本更新的资源
- 411 Length Required:如果请求含有包体且未携带Content-Length头部,且不属于chunk类请求,返回411(非常容易构造,加入包体但是又不加入conten-length,也不加入chunk类的相关的描述)
- 412 Precondition Failed:(条件类请求不满足的时候,就会返回412)复用缓存时传递的If-Unmodified-Since或者If-None-Match头部不被满足
- 413 PayloadTooLarge/Request Entity Too Large:请求的包体在超出服务器能处理的最大长度(wordpress默认长传的附件可能只有2M,就是wordpress的插件,通常需要去把默认的2M向上去调整,就不再得到413这样的错误了。)
- 414 URI Too Long:请求的URI超出服务器能接受的最大长度(如果是比较老的服务器,那么对URI通常限制是4k,像nginx这样的比较新的版本服务器,通常限制可能达到了32k。所以我们去验证也是很容易的,我们发一个巨大的URI,超出了服务器能处理的最大长度,我们就会得到414)
- 415 Unsupported Media Type:(上传的请求包体对应的文件类型,就是mime类型,是不被服务器所支持的,比如说我们搭建了一个wordpress的站点,它就通常默认是拒绝exe这样的可执行文件,直接出传递,防止有安全的风险。这个时候客户端就会收到415这样的一个错误码,我们就知道只因为服务器认为这个文件类型暂时不被支持)上传的文件类型不被服务器支持。
- 416 Range Not Satisfiable:(对于多线程断点续传下载,指定中一段包体是不支持的,比如我们指定从1G到2G这段,但实际上这个文件可能只有100M)无法提供Range请求中指定的那段包体
- 417 Expectation Failed:(比如客户端发送中包括Expect 100,我要上传一个巨大的文件了,我期待你给我一个100,但是如果说服务器不支持的情况下,没有办法满足这个要求,它就会返回417)对于Expect请求头部期待的情况无法满足时的响应码
- 421 Misdirected Request:服务器认为这个请求不该发给它,因为它没有能力处理。(很少能在网络中见到)
- 426 Upgrade Required:服务器拒绝基于当前HTTP协议(比如说HTTP 1.1,要求客户端必须基于更新的,比如说websocket,或者是HTTP2.0,我才提供服务,这个时候就会返回426)提供服务,通过Upgrade头部告知客户端必须升级协议才能继续处理。
- 428 Precondition Required:用户请求中缺失了条件类头部,例如If-Match(跟条件请求相关)
- 429 Too Many Request:客户端发送请求的速率过快(很多服务器限流限速的时候,往往不会给客户端发429,虽然RFC规范中429是更明确的告诉客户端这样一件事情,但是往往我们会发送503,在5系列响应码中再详细介绍)
- 431 Request Header Fields Too Large:请求的HEADER头部大小超过限制(可以看出这里的规范定义的实在是太细了,因为我们刚刚去限制了URI如果特别大的时候,返回了一个414的这样的响应码,431又对于Header去做了一个限制,实际上很多服务器是不会去做这么严格的错误码的返回的,通常都只会返回这个414 URI Too Long,因为URI和Request Too Long往往在服务器中作为同一段缓存区去存储处理的)
- 451 Unavaiable For Legal Reasons:RFC7725,由于法律原因资源不可访问
- 5xx:服务器端出现错误
- 500 Internal Server Error:(这可能是我们最常见的一种错误,就是这个内部错误已经没有办法细分了)服务器内部错误,且不属于一下错误类型
- 501 Not Implemented:服务器不支持实现请求所需要的功能(当前请求执行的功能我们现在还没有去实现,需要服务器端去升级或者说添加相应的功能)
- 502 Bad Gateway:(非常常见的错误码,在与服务器之间有代理服务器,但是这个代理服务器连接不上源服务器,或者说代理服务器没有办法从我们的源服务器中获取到合法的一个响应,这是502 Bad Gateway)代理服务器无法获取到合法响应
- 503 Service Unavailable:服务器资源尚未准备好处理当前请求(实际上会有很多种原因导致503出现,比如服务器端做请求的限速,或者说去对于用户的ip做并发连接的限制,那么当达到上限的时候呢,都有可能去发送503,表示我们服务器的资源还没有准备好处理当前请求)
- 504 Gateway Timeout:代理服务器无法及时的从上游获得响应(代理服务器与我们的源服务器之间出现了超时,比如我们现在上传一个巨大的文件,或者下载一个巨大的文件,但是我们的代理服务器,例如nginx,它配置的超时时间是1分钟,那如果1分钟之内源服务器还没有及时的响应它,那么代理服务器就会给客户端发送一个504 Gateway Timeout。所以看到我们应该立即反应出来,是代理服务器上的超时时间设置的可能过小)
- 505 HTTP Version Not Supported:请求使用的HTTP协议版本不支持(比如说有一些服务器不支持HTTP 2.0,但是我们构造了一个2.0的请求,就会得到这样的响应。我们去验证它也非常的容易,比如GET / HTTP/2.0。)
- 507 Insufficient Storage:服务器没有足够的空间处理请求(通常是指磁盘空间,所以507这个错误码已经把服务器内部的相关的问题暴露给客户端了,所以通常507是不被我们见到的,因为这里会有安全性的问题)
- 508 Loop Detected:访问资源时检测到循环(或者说循环已经超过了最大的限制次数了,就会返回508 Loop Detected)
- 511 Network Authentication Required:代理服务器发现客户端需要进行身份验证才能获得网络访问权限(也是同样在机场、网吧等这样的场景我们经常会见到)
小结
这篇文章介绍了客户端出现错误时的400系列错误响应码,以及服务端出现错误时的500系列错误响应吗,那么与上篇文章中介绍的100、200、300系列响应码中,它们还遵循一个潜在的规则,就是当客户端接收到了,一个它不认识的响应码,不知道如何处理的时候,将按照它们所在系列的第一个,就是00系列那个响应码逻辑进行去处理,比如说我们现在收到了一个555这样的响应码,客户端不认,就会按照500的处理逻辑。如果收到了一个277,那么也会按照200这个错误码的处理逻辑来处理。
参考
陶辉老师的Web协议详解与抓包实战课程
HTTP的正确响应码(For Reference)
100,200,300系列表示成功的响应码
- 响应码规范:RFC6585(2012.4)、RFC7231(2014.6)
- 1xx:请求已接收到,需要进一步处理才能完成,HTTP1.0不支持
- 100 Continue:上传大文件前使用
- 由客户端发起请求中携带Expect 100-continue头部触发
- 101 Switch Protocols:协议升级使用
- 由客户端发起请求中携带Upgrade:头部触发,如升级websocket或者http/2.0
- 102 Processing:WebDAV请求可能包含许多涉及文件操作的子请求,需要很长时间才能完成请求。该代码表示服务器已经收到并正在处理请求,但无响应可用。这样可以防止客户端超时,并假设请求丢失
- 100 Continue:上传大文件前使用
- 2xx:成功处理请求
- 200 OK:成功返回了响应
- 201 Created:有新资源在服务器端被成功创建
- 202 Accepted:服务端接受并开始处理请求;但请求未处理完成。这样一个模糊的概念是有意如此设计,可以覆盖更多的场景。例如异步、需要长时间处理的任务。先给客户端返回202 Accept,而由异步的任务继续去处理这个任务。
- 203 Non-Authoritative Information:当代理服务器修改了origin server的原始响应包体时(例如更换了HTML中的元素值),代理服务器可以通过修改200为203的方式告知客户端这一事实,方便客户端为这一行为做出相应的处理。203响应可以被缓存。203这个规范并不被广为接受。
- 204 No Content:成功执行了请求且不携带响应包体,并暗示客户端无需更新当前的页面视图。(常见与我们用put等方法post等方法上传了一些资源但是返回的响应告诉不需要去刷新当前的URI等。)
- 205 Reset Content:成功执行了请求且不携带响应包体,同时指明客户端需要更新当前页面视图。(比如说URI画图等,可能会遇到)
- 206 Partial Content:(多线程断点续传下载都会使用到range协议)使用range协议时返回部分响应内容时的响应码
- 207 Multi-Status:RFC4918,在WEBDAV协议中以XML返回多个资源的状态。(返回目录树的结构的时候,实际上是返回了很多个子目录及其相关的资源描述,那么这个时候我们其实有很多个响应码,那么207就是把这些响应作为一个响应的时候,那么这个响应码我们告诉客户端是207)
- 208 Already Reported:RFC5842,为避免相同集合下资源在207响应码下重复上报,使用208可以使用父集合的响应码。
- 3xx:重定向使用Location指向的资源或者缓存中的资源。在RFC2068中规定客户端重定向次数不应超过5次,以防止死循环。
- 300 Multiple Choices:资源有多种表述,通过300返回给客户端后其自行选择访问哪一种表述。由于缺乏明确的细节,300很少使用。
- 301 Moved Permanently:资源永久性的重定向到另一个URL中。(浏览器可以对永久性的重定向直接缓存)
- 302 Found:资源临时的重定向到另一个URL中。
- 303 See Other:重定向到其他资源,常用语POST/PUT等方法的响应中。
- 304 Not Modified:当客户端拥有可能过期的缓存时,会携带缓存的标识etag、时间等信息询问服务器缓存是否仍可复用,而304是告诉客户端可以复用缓存。
- 307 Temporary Redirect:类似302,但明确重定向后请求方法必须与原请求方法相同,不得改变。
- 308 Permanent Redirect:类似301,但明确重定向后请求方法必须与原请求方法相同,不得改变。
参考
陶辉老师的Web协议详解与抓包实战课程
阿甘正传经典台词-you have to do the best with what God gave you
- Well...I happen to believe you make your own destiny. You have to do the best with what God gave you.
从五种架构风格推导出HTTP的REST架构
在分布式的Web架构中呢,有5类架构风格。那么什么叫架构风格呢?我们在日常编程中可能会有习惯用法,再高一级在面向对象语言中呢,可能会有设计模式,那么再往上更大粒度的抽象我们可以用到架构。而架构风格是指某一类架构它们具有相同的或者说类似的一些约束,我们把它归纳为一类架构风格。那么我们rest架构,也就是HTTP设计所遵循的这样的架构会使用到我们下面的,或者说参考我们下列5类架构风格中的其中一些架构。
那么这5类架构风格呢,主要包括:
- 数据流风格 Data-flow Styles(协议的分层,nginx)
- 优点:简单性、可进化性、可扩展性、可配置性、可重用性
- 复制风格 Replication Styles
- 优点:用户可察觉的性能、可伸缩性、网络效率、可靠性也可以得到提升
- 分层风格 Hierarchical Styles
- 优点:简单性、可进化性、可伸缩性
- 移动代码风格 Mobile Code Styles
- 优点:可移植性、可扩展性、网络效率
- 点对点风格 Peer-to-Peer Styles
- 优点:可进化性、可重用性、可扩展性、可配置性
数据流风格Data-flow Styles
- 管道和过滤器Pipe And Filter,PF
- 每个Filter都有输入端和输出端,只能从输入端读取数据,处理后再从输出端产生数据(协议,TCP-ip-数据链路层协议,只能从输入端到输出端)
- 统一接口的管道与过滤器 Uniform Pipe And Filter, UPF
- 在PF上增加了统一接口的约束,所有Filter过滤器必须具备同样的接口
主要这种数据流风格会对简单性上有所体现,特别是UPF以后简单性会有很大的提升,我们每一个模块每一个Filter都可以独自的去升级进化不影响。那么我们再增加一个新的功能,比如说增加一个新的协议层,或者说nginx增加一个新的模块,都是很容易的,所以可扩展性也是非常好的。那么可配置性也是一样的,我们可以通过配置文件灵活的去增加我们的Filter或者说我们的协议层级,而在我们的可重用性上面也是非常好的。每一个Filter我们会独立的拿下来以后给新的这样的一种架构去使用。
复制风格Replication Styles
- 复制仓库Replicated Repository,RR
- 多个进程提供相同的服务,通过反向代理对外提供集中服务(MySQL冷热备份,Web app同时提供很多服务、使用nginx反向代理)
- 缓存$
- RR的变体,通过复制请求的结果,为后续请求复用
复制仓库与缓存这两种架构,对于用户可察觉的网络性能,RR和$风格因为都会对用户能够觉察到的性能有一个提升。缓存风格呢,因为直接减少了网络的传输量,所以网络效率会更高一些,那scalability呢,可伸缩性,因为有很多可以复制的进程或者可以复制的数据,也会导致我们scalability更好。简单性上,缓存风格也会表现更好一些。因为我有多个进程多个服务,所以可靠性上也会更好一些。
分层风格Hierarchical Styles
- 客户端服务器Client-Server, CS(HTTP)
- 由Client触发请求,Server监听到请求后产生响应,Client一直等待收到响应后,会话结束
- 分离关注点隐藏细节,良好的简单性、可伸缩性、可进化性(Server只关注资源的响应的生成,资源的管理,Client就关注于网络和结果可视化的渲染。向对方都隐藏了各自的细节,所以它们的简单性相对比较好,我们只关注中间的协议,而不关注可视化或者说数据库的管理。可伸缩性:比如Server在不停地增加更多的服务的节点,我们就可以为client提供更高可用性的服务。可进化性,意味着我们client和server都可以独立的进行进展)
- 分层系统Layered System, LS
- 每一层为其上的层服务,并使用在其之下的层所提供的服务,例如TCP/IP,OSI
- 分层客户端服务器Layered Client-Server, LCS
- LS+CS,例如正向代理和反向代理,从空间上分为外部层与内部层(正向代理,客户端和整个网络环境分离,反向代理把企业内网和整个企业外面的Internet网络进行了分层
- 无状态、客户端服务器Client-Stateless-Server CSS
- 基于CS,服务器上不允许有session state会话状态
- 提升了可见性、可伸缩性、可靠性,但重复数据导致降低网络性能(HTTP 2.0的很多升级都体现在这几个方面,HTTP2.0中不希望重复的传递HTTP的头部,因为HTTP的头部特别是Cookie占用了网络资源,就是HTTP2.0已经做不到无状态了,所以它的重复数据相对比较少,网络性能更高,但是可见性、可伸缩性、可靠性上,相对较差一些。
- 缓存、无状态、客户端服务器Client-Cache-Stateless-Server-C$SS
- 提升性能(因为有重复数据,因为反复传递相同的header,环节可能导致的问题)
- 分层、缓存、无状态、客户端服务器Layered-Client-Cache-Stateless-Server, LC$SS
client connector, client+cache, server connector, server+cache
- 远程会话Remote Session, RS
- CS变体,服务器保存Application State应用状态(FTP)
- 可伸缩性(不可能任意扩充服务器而对客户端没有影响)、可见性差(因为我单独的抓取一个报文,分析一个报文是没有办法得到完整的请求信息的)
- 远程数据访问Remote Data Access, RDA
- CS变体,Application state应用状态同时分布在客户端与服务器(SQL访问,因为我们的查询集可能包含几百万条数据,所以我们必须要用到游标cursor,反复的一页一页地获取数据,也就是使得我们的客户端保存了一个应用的状态,我当前查询到第几页,而服务器端也需要为游标来保存这样的相应的数据)
- 巨大的数据集有可能通过迭代而减少整个数据集
- 简单性、可伸缩性差(我们传统的关系型数据库很少能够支持这种高可用性,基于数据仓库的多个热备份的分布式架构,是很难达到的)
由服务器来保存客户端的架构都会导致scalability很差,所以我们HTTP协议所依赖的Rest架构不使用这两种方式。特别是加入分层,加入CS架构以后,scalability是非常优秀的,简单性也是因为我们加入分层统一无状态以后,得到了很大的提升。可进化性因为所有基于client server这种分离关注点的情况下,我们的可进化性都是比较优秀的。而在可重复使用上,特别是基于分层属性后,都会有很大的一个提升。而在可见性上,因为我加入了一个stateless,无状态,无状态的情况下每一条请求都携带了全部的信息,所以我的可见性会更好。那么可移植性,也是基于分层以后可移植性有了很大的提升。可靠性呢,因为我们有了无状态有了缓存以后,我们的可靠性也得到了提升。
移动代码风格Mobile Code Styles
(表示实际程序要执行的那个代码是可以任意的从客户端到服务器端移动的)
虚拟机Virtual Machibe, VM
- 分离指令与实现(公有云、基于KVM,Java的虚拟机)
远程求值Remote Evaluation, REV
- 基于CS的VM,将代码发送至服务器执行
按需代码Code on Demand,COD
- 服务器在响应中发回处理代码,在客户端执行(JS脚本)
- 优秀的可扩展性和可配置性,提升用户可察觉性能和网络效率
分层、按需代码、缓存、无状态、客户端服务器
Layered-Code-on-Demand-Client-Cache-Stateless-Server, LCODC$SS
- LC$SS+COD
移动代理Mobile Agent,MA
- 相当于REV+COD
REV的安全性风险太大
统一接口的LC$SS+COD的架构
用户可察觉的网络性能,网络性能,可伸缩性,可进化型,可扩展性,可配置性,可见性,可重用性
Peer-to-Peer Styles
Event-based Integration,EBI
- 基于事件集成系统,如由类似kafka,Rabbit MQ这样的消息系统+分发订阅来消除耦合
- 优秀的可重用性、可扩展性、可进化性
- 缺乏可理解性
- 由于消息广播等因素造成的消息风暴,可伸缩性差
Chiron-2,C2
参见论文《A Component-and Message-Based Architectual Style for GUI Software
- 相当于EBI+LCS,控制了消息的方向
Distruibuted Objects,DO
- 组件结对交互
Brokered Distributed Object,BDO
- 引入名字解析组件来简化DO,例如CORBA
风格演化到rest
避免熵增
- 心流的状态
TLS与量子通讯的原理
TLS保证安全性的最大难题在于如何传递后续对称加密时,所使用的密钥,那么目前所使用的DH或者DHCE协议呢,都存在被快速运算的计算机所破解的一个可能性。那么,接下来将介绍量子通讯协议。当然这里的量子通讯与我们在物理学中所了解到的那个量子力学一点关系都没有,只是借用了其中一些理念而已。
我们首先来看一下量子通讯的理论基础。
TLS密码学回顾
- 通讯双方在身份验证的基础上,协商出一次性的、随机的密钥(我们上文中所介绍过的session id和session ticket还有0RTT都违反了一次性这个原则,所以呢我们也需要用时间来做限制,往往几个小时,或者几天之内必选要过期等等)(什么叫随机呢?我们使用DH系列协议的时候呢,生成的这个私钥必须基于硬件的或者说相对可靠的这样的一个随机算法,来生成随机的这样的一个私钥。那么后续才能够保证我们这个密钥是可靠的)
- PKI公钥基础设施(身份验证)
- TLS中间件生成一次性的、随机的密钥参数
- DH系列协议基于非对称加密技术协商出密钥(协商)
- 使用分组对称加密算法,基于有限长度的密钥将任意长度的明文加密传输
- 密钥位数
- 分组工作模式(AES, GCM)
香农曾经在信息论中证明过:
- 证明one-time-pad(OTP)的绝对安全性
- 密钥是随机生成的
- 密钥的长度大于等于明文长度
- 相同的密钥只能使用一次(重放攻击,session id, session ticket等)
- 如何传递密钥?
量子通讯可以解决这个问题:
量子通讯有一个概念叫量子密钥分发quantum key distribution,简称QKD
借用了量子力学中的一个概念:任何对量子系统的测量都会对系统产生干扰
这个概念是怎样完成的呢?QKD:如果有第三方试图窃听密码,则通信的双方便会察觉(回顾一下中学中学过的光的波粒二象性,我们知道光有粒子的特性,它还有波的特性。波是有方向,比如说我们看下面这张图,黄色的是垂直的方向,通过一个光栅,会导致垂直方向的波可以通过光栅的,但是横着走的光波是没有办法通过光栅,也就是说,不同方向的光波通过光栅时,通过率是不同的。)
(那么接下来要说的量子通讯就基于这样的一个原理。它的原理是,当双方进行通讯时,如果有第三方接收到我们的信息再进行转发的时候,通信的双方都可以察觉到。它们怎么察觉到呢?是基于概率来进行的。比如双方的通讯的时候,我们传递密钥的时候,它的正确率,信息正确率是75%。那么每增加一个中间第三方的环节就是75%*75%,数据的正确率大幅的下降了,通过这样的一种,我们就像量子系统一样,任何对其进行测量,或者说我们叫做窃听密码,通讯的双方都可以察觉到。)
小结
量子通讯是基于光波来传递密钥的,那么它是借用了量子力学中的系统不可测的这样的一个原理,所以叫做量子通讯。那么,接下来我们将介绍BB84协议,它会跟我们演示如何根据通过量子通讯来传递密钥,而且我们也可以通过概率发现是否有第三方窃听数据。
基于通过光栅时,不同方向的光波的通过率是不同的,那么我们将基于这一原理,来演示BB84协议是如何使量子通讯成为现实的。
BB84协议
由Charles Bennett与Giles Brassard在1984年发表
2017年中国发射的墨子号量子通讯卫星,所使用的量子通讯协议,只是一个BB84协议的升级版。所以我们理解最先出现的BB84协议,对我们理解当下正在快速发展中的量子通讯是非常有意义的。
图中呢,我们画出了两种不同的光栅,这两种光栅呢,一种是垂直的,一种是倾斜45°的。这两种光栅把它称为基或者叫basis,那么这种光栅下只能通过两种不同方向的光波。那么我们把向上的这种光波理解为二进制中的1,水平的是0,还有一种是45°的光栅,在这种光栅下呢,我们把斜向上的我们称为0,斜向下的我们称为1。那么现在有个问题,如果是一个横向的垂直的光波,通过这样一个X状的,斜着45°的状的这样的一个光栅时,究竟会能不能通过呢?可以通过。它有一些会被反射为这样的0,有一些会被反射为1,就是完全是随机的。
我们来看一个具体的例子。比如Alice现在想给Bob来传递我们后续对称加密所要使用的这样的密钥,那么它要传递的一个数字信息呢是10110011001110,那么它首先自己会有一个光栅,也就是我们所谓的basis。它的basis究竟是采用斜的还是垂直的Bob是不知道的。而Alice使用当中它也是随机产生的。那么每一个1或者0它都会采用不同的光栅,发射出去的光波是这样的,有的是垂直的有的是斜的,根据它的0和1信息,而Bob检测的时候呢,它也要使用一个光栅,那么他也在随机的选用一个叉或者是一个垂直的加号作为光栅,这个时候呢根据我们刚刚所介绍的光波的一个原理,它能够获得到的信息是这样的。那么这个信息和实际Alice要发射的信息,如果信息量足够大的话,它的正确率是多少呢?正确率是75%。或者我们这样去看,它的错误率是25%。为什么是25%呢?首先,Bob的光栅和Alice的光栅完全一致的概率是50%,那么在完全一致的情况下,它们的数据肯定是完全是正确的,那么还有一种我不一致的时候也不一定是完全错误的,因为我不一致的时候其实是有一半的几率正确,一半的几率错误,虽然我是不一致的光栅的方向。所以我们的错误率是25%,那么我们的正确率自然就是75%,如果中间有一个人,开始做中间人,监听了以后,再反射到Bob的话呢。其实中间人这块它的正确率是75%,那么Bob这一块呢就是75%*75%,大概是55%。因为我们的BB84协议呢最后是需要Bob把他所检测到的这个10010011000100这段信息发送给Alice,Alice根据它的一个错误率或者说正确率来判定中间有没有中间人在监听。如果没有中间人在监听呢,那么他还会重新一个叫密钥纠错的这样的一个阶段呢,告诉Bob,你用的那些光栅的方向是对的,那么你只取这些光栅方向是对的这样的一个数据,作为我们后续的通讯的密钥,这样就可以了。可能上述的流程有一些抽象,我们可以看一个实际的例子:
Alice's bit 01101001
Alice's basis ++x+xxx+
Alice's polariztion ↑→↖↑↖↗↗→
Bob's basis +xxx+x++
Bob's measurement ↑↗↖↗→↗→→
Public discussion
Shared Secret key 0-1--0-1
Alice 要给Bob传递 01101001 这段信息。Alice的basis光栅是随机的,但是Alice非常清楚,每传递的一个数据所对应的光栅到底是什么方向,她自己是很清楚的,所以这时候Alice所传出来的光波的方向是已经确定下来了,那么Bob在接收这些光波的时候呢,他所采用的这样的一个光栅呢,有时候是与Alice一致的有时候是不一致的。Bob他所检测到的这个光波的方向是换算成01肯定是有一定的错误率的。Bob就会把他换算出来的数据,以及他所使用的方向,都发给Alice。那么Alice根据这个错误率或者说正确的概率,判定没有中间人,那么Alice就可以告诉Bob,哪些光栅的方向与我的方向是完全一致的,这样的相应对应的数据就可以拿来做我们后续加密时所使用的对称加密的这样的一个密钥。那么这样的话我们就把QKD中的密钥分发中密钥纠错和隐私增强也介绍了。
TLS/SSL协议小结
我们首先使用到了对称加密所使用到的一些技术,尤其我们重点介绍了AES算法,以及GCM分组工作模式,那么接下来我们介绍了非对称加密算法的两种应用。首先是在PKI证书体系,其次是在DH或者DHCE密钥交换协议中得到了大量广泛的使用。我们也介绍了TLS1.3协议,那么在未来TLS1.3协议将会得到大量广泛的使用,我们必须清楚TLS1.3协议究竟做了哪些改进,和优化。
TLS协议的安全性受限于当下最快的计算机的运行速度,所以呢,我们也介绍了理论上绝对安全的量子通讯方式来传递密钥。
那么之后我们将介绍TLS层次下的传输层协议(TLS属于表示层协议),我们将重点介绍TCP协议的设计原则和众多特性。
TLS握手的优化:session缓存、ticket票据及TLS1.3的0-RTT
TLS握手中所消耗的一个或者两个RTT的时间,是用于安全性,对于我们应用层的信息传递而言并没有意义。所以TLS提供了许多种手段,比如缓存,ticket等等,用于减少我们TLS握手中所消耗的RTT的时间。接下来简要介绍常用的一些手段,以及它们所存在的问题。
session缓存:以服务器生成的session ID为依据
session resume with session ID
最常用的叫session 缓存
第一次握手后,服务器会生成一个session ID,这个session ID会传给浏览器,或者说是client,当在一定的时间以内,比如说几个小时或者几天以内,浏览器或者客户端携带着这个session ID,再次访问服务器的时候,服务器这个时候它从它的内存或者说其他的缓存中,取到了这个session ID所对应的加密密钥,那么服务器就可以跟client说,我们就使用上一次所使用的加密密钥就可以了,没有必要使用DH或者DHCE密钥交换协议再次生成一个加密密钥,这样我们就减少了RTT。那么这里对于client和server都有要求。client需要在一定的时间内缓存住session ID以及它所对应的加密密钥,而服务器也需要在它的缓存中,为session ID缓存一定的时间。
第二次访问的时候,Client Hello中是有一个session ID的,当然,第一次访问的时候是没有这样的一个数字的。有了这样的一个session ID以后呢,Server Hello返回了Change Cipher Spec Message,而没有发送Server Key Exchange,就是我们DHCE中必须要发送公钥这么的一个步骤。Change Cipher Spec中说了些什么呢?我们可以看到,[Expert Info (Note/Sequence): This session reuses previously negotiated key (Session resumption)],我们使用上一次所协商过的key就可以了。服务器就使用了内存所缓存的session id所对应的密钥。接下来所有的通讯都是基于我们上一次所使用的密钥进行加密的。
session ID缓存往往会有两个问题:
- server 往往是在内存中存放session id以及对应的密钥信息的,所以位于不同的主机上的server它们是没有办法去分享它们的session id以及对应的密钥信息,然而实际上我们的服务往往都是服务于成千上万个用户,所以要通过反向代理负载均衡等通过一个ip或者一个域名,来为很多个用户服务,所以我们会有很多台server,这些server中如何去共享这些个session id呢,比如说server A为同一个用户所生成的session id当下一次用户来访问的时候,很可能通过负载均衡,访问到了server b,那么server b又需要重新进行握手了,这是第一个问题。
- 第二个问题,server在内存中存储session id是有内存消耗的。那么到底缓存多长时间,过短和过长都不合适。
这个时候就可以考虑session ticket,session ticket处理方式与session 缓存是完全不同的,那首先我们的每一台server不需要再耗费内存去存放每一个session中所需要的信息,而是基于它所独有一个密码,那么这个密码呢是整个集群中所共同分享的一个密码,基于这个密码把相关的加密信息进行加密,发送给客户端,那么当客户端下一次需要握手的时候呢,把这个相关的加密后的信息发送给服务器,而只有这个集群内的服务器才知道这个密码,那么它基于这个密码解密之后,就获取到上一次握手成功后所需要的密钥,我们就可以基于这个密钥,与client中所缓存的这个密钥进行加密数据的一个通讯。这样我们就解决了session缓存所具有的上面的问题了。
TLS1.3的0RTT握手
我们知道TLS1.3中只需要一次RTT完成握手。所谓的0RTT是指,第一次握手的时候就携带我们相关的数据,比如说我们有一个Get请求,第一次就发送,那么在一个RTT后呢,我们就可以收到response,所以它实现握手没有占用任何的RTT。我们叫它0RTT。那么它们是怎么实现的呢?实际上,它们是第二次握手才可以完成的,因为当我们第一次握手的时候,我们的client和服务器呢会把相关的密钥信息缓存下来,那么第二次握手的时候我们基于上一次缓存的一定时间内有效的信息,对我们的Get请求进行加密,那么发送给server,如果server也认为这个上一次的密钥相关信息没有过期的话,那么它就可以解密到了,也可以把基于同样的密钥,把相应的response发给client。
当然,无论是session ID缓存或者是session ticket或者TLS1.3中的0RTT,它们其实都面临着同样一种攻击叫做重放攻击。那么什么叫重放攻击呢?比如说我们的client现在发送了一个post请求,那么这个post请求呢使用上一次中所使用到的密钥进行加密,所以这其实是一个报文,一个packet,这个packet发送给server呢,server是认的,因为它马上利用它所没有过期的密钥进行解密,并处理,通常一个post请求很有可能是改变我们的用户的数据状态的,那么就改变了我们的数据库。如果这个报文被我们的一个中间人在某个路由器或者某一个代理服务器中把这个报文保存下来了,那么它就可以在随后的过程中,不需要去解密相关的信息,我只要这个packet不停地重新地再发送,就可以不停地去改变我们的数据库的状态。这就是一个重放攻击。
所以我们的0RTT,或者说我们session id、ticket reuse都是需要设定一个合适的合理的过期时间的。
小结
本片文章主要介绍了TLS为了提升握手速度,而进行的性能优化手段,而TLS中所面临的另外一个问题,就是它的安全性,非常依赖于当前最快速的计算机的运行速度。那么有没有一劳永逸的绝对安全的这样的一种通讯手段呢?那么量子通讯可以带给大家全新的思考。
中华民族的脊梁,不是被众人扶持起来的
中华民族的脊梁,不是被众人扶持起来的,就是因为我们有这样的英雄,这样的精英。我们的民族的脊梁今天才能挺立。-- 纪念杨靖宇和抗日战争胜利75周年
誓干惊天动地事,敢做隐姓埋名人。 -- 黄旭华