向死而生,面向死亡生活
第一,存在者(人)的本命工作应该是:在有限的时间里,去呼应和思考存在者自己存在于这个世界上的依据,即存在者(人)要思考“存在”问题。
第二,存在者(人)存在于这个世界上的时间是有限的,因为“死亡”是必然到来和发生的“潜在可能性”,所以存在者(人)会害怕“死亡”。那什么能够让我们暂时遗忘它、不去害怕它呢?那就是让自己忙起来,让自己操劳于世,这样就不会感到害怕。
当第一种情况遇上第二种情况的时候,有限的时间使得存在者(人)必须二选其一进行工作。海德格尔认为,我们应该选择第一种情况,即在有限的时间里去追问自己存在的依据问题,而不能只是活着(PS:这也是人活着的意义问题、人的安身立命之所和人的价值所在)。
海德格尔怎么让人摆脱对”死亡“的恐惧状态呢?于是,”向死而生“这个概念就出来了。海德格尔意义上的”向死而生“是为了鼓励人们回归对本命工作的工作状态,继续追问”存在“、关心人的意义问题和价值问题。这是终极问题,而”向死而生“只是这个目标的一个环节中针对某个问题的态度和对策。
面向死亡生活,面向存在生活。不是害怕,是不停的问自己存在的意义。
链接:https://www.zhihu.com/question/304682444/answer/781917577 来源:知乎
Egor in the Republic of Dagestan
题意:
给出n个点和m条边的有向图,每条边的长度为1,有一个属性由0或1表示,现在需要给每个节点赋值,使得:
- 如果点u的权值为0,则u只能走(u,v)且这条边的属性为0的边。
- 如果点u的权值为1,则u只能走(u,v)且这条边的属性为1的边。
问如何赋值能让点1到点n的最短路径最大,输出一种构造方案。
思路:
这是一道dp题。
首先要先去除自环,因为要走最短路,这个肯定没有意义。
设dp_i,col表示第i个点涂上col这个颜色走到终点最短路最长是多少。
转移也非常好想:dp_i_col = min{max(dp_j,0,dp_j,1) + 1},(edge{i, j, col ∈ E}
肯定是小的更新大的,所以最短路转移就好了。
另外,由于dp_j,0与dp_j,1取了一个max,所以如果用j来更新i的话,必须是第二个出现的。我们可以记录一个cnt。
初始化dp_n,0 = dp_n,1 = 0。
答案 = max(dp_1,0,dp_1,1)。
最后考虑第 i 个点。
- dp_i,0 > dp_i,1,col_i = 0
- dp_i,0 < dp_i,1,col_i = 1
1 | /* |
曾经我也想过一了百了--中岛美嘉
那时我,也曾想过,坠入无边星河。活着要比死亡有更大的勇气吧,虽然没死过。但是死亡就可以不用面对,而活着就要面对一切。或许是活着的人觉得死亡需要勇气,而自杀的人的觉得活着需要勇气。只要活着,就积极的活着吧!像中岛美嘉一样!
坚强!
每天写150-200行有效代码
如何利用面向对象设计和编程开发接口鉴权功能?
在上一篇文章中,针对接口鉴权的开发,我们讲了如何进行面向对象分析(OOA),也就是需求分析。实际山,需求定义清楚之后,这个问题就已经解决了一大半,这也是为什么要画那么多篇幅来讲解需求分析。今天,我们再来看一下,针对面向对象分析产出的需求,如何来进行面向对象设计(OOD)和面向对象编程(OOP)。
如何进行面向对象设计?
我们知道,面向对象分析的产出是详细的需求描述,那面向对象设计的产出就是类。在面对对象设计环节,我们将需求描述转化为具体的类的设计。我们把这一设计环节拆解细化一下,主要包含一些几个部分:
- 划分职责进而识别出有哪些类;
- 定义类及其属性和方法;
- 定义类与类之间的交互关系;
- 将类组装起来并提供执行入口。
实话讲,不管是面向对象分析还是面向对象设计,理论的东西都不多,所以我们还是结合鉴权这个例子,在实战中体会如何做面向对象设计。
1.划分职责进而识别出有哪些类
在面向对象有关书籍中经常提到,类是现实世界中事物的一个建模。但是,并不是每个需求都能映射到现实世界,也并不是每个类都与现实世界中的事物一一对应。对于一些抽象的概念,我们是无法通过映射现实世界中的事物的方式来定义类的。
所以,大多数讲面向对象的书籍中,还会讲到另外一种识别类的方法,那就是把需求描述中的名词罗列出来,作为可能的候选类,然后再进行筛选。对于没有经验的初学者来说,这个方法比较简单、明确,可以直接照着做。
不过,我个人更喜欢另外一种方法,那就是根据需求描述,把其中涉及的功能点,一个一个罗列出来,然后再去看哪些功能点职责相近,操作同样的属性,是否应该归为同一个类。我们来看一下,针对鉴权这个例子,具体该如何来做。
在上一篇文章中,我们已经给出了详细的需求描述,为了方便你查看,我把它重新贴在了下面。
- 调用方进行接口请求的时候,将URL、AppID、密码、时间戳拼接在一起,通过加密算法生成token,并且将token、AppID、时间戳拼接在URL中,一并发送到微服务端。
- 微服务端在接收到调用方的接口请求之后,从请求中拆解出token、AppID、时间戳。
- 微服务端首先检查传递过来的时间戳跟当前时间,是否在token失效时间窗口内。如果已经超过失效时间,那就算接口调用鉴权失败,拒绝接口调用请求。
- 如果token验证没有过期失效,微服务端再从自己的存储中,取出AppID对应的密码,通过同样的token生成算法,生成另外一个token,与调用方传递过来的token进行匹配。如果一致,则鉴权成功,允许接口调用;否则就拒绝接口调用。
首先,我们要做的是逐句阅读上面的需求描述,拆解成小的功能点,一条一条罗列下来。注意,拆解出来的每个功能点要尽可能的小。每个功能点只负责做一件很小的事情(专业叫法是“单一职责”,后面章节中我们会讲到)。下面是我逐句拆解上述需求描述之后,得到的功能点列表:
- 把URL、AppID、密码、时间戳拼接为一个字符串;
- 对字符串进行加密算法加密生成token;
- 将token、AppID、时间戳拼接到URL中,形成新的URL;
- 解析URL,得到token、AppID、时间戳等信息;
- 从存储中取出AppID和对应的密码;
- 根据时间戳判断token是否过期失效;
- 验证两个token是否匹配;
从上面的功能列表中,我们发现,1、2、6、7都是跟token有关,负责token的生成、验证;3、4都是在处理URL,负责URL的拼接、解析;5是操作AppID和密码,负责从存储中读取AppID和密码。所以,我们可以粗略的得到三个核心的类:AuthToken、Url、CredentialStorage。AuthToken负责实现1、2、6、7这四个操作;Url负责3、4两个操作;CredentialStorage负责5这个操作。
当然,这是一个初步的类的划分,其他一些不重要的、边边角角的类,我们可能暂时没法一下想全,但这也没关系,面向对象分析、设计、编程本来就是一个循环迭代、不断优化的过程。根据需求,我们先给出一个粗糙版本的设计方案,然后基于这样一个基础,再去迭代优化,会更容易一些,思路也会更更加清晰一些。
不过,我还要再强调一点,接口调用鉴权这个开发需求比较简单,所以,需求对应的面向对象设计并不复杂,识别出来的类也并不多。但如果我们面对的是更加大型的软件开发、更加复杂的需求开发,涉及的功能点可能会很多,对应的类也会比较多,像刚刚那样根据需求逐句罗列功能点的方法,最后会得到一个长长的列表,就会有点凌乱、没有规律。针对这种复杂的需求开发,我们受邀作的时进行模块划分,将需求先简单划分成几个小的、独立的功能模块,然后再在模块内部,应用我们刚刚讲的方法,进行面向对象设计。而模块的划分和识别,跟类的划分和识别,是类似的套路。
2.定义类及其属性和方法
刚刚我们通过分析需求描述,识别出了三个核心的类,它们分别是AuthToken、Url和CredentialStorage。现在我们来看下,每个类都有哪些属性和方法。我们还是从功能点列表中挖掘。
AuthToken类相关的功能点有四个:
- 把URL、AppID、密码、时间戳拼接为一个字符串;
- 对字符串通过加密算法加密生成token;
- 根据时间戳判断token是否过期失效;
- 验证两个token是否匹配。
对于方法的识别,很多面向对象相关的数据,一般都是这么讲的,识别出需求描述中的动词,作为候选的方法,再进一步过滤筛选。类比一下方法的识别,我们可以把功能点中涉及的名词,作为候选属性,然后同样进行过滤筛选。
我们可以借用这个思路,根据功能点描述,识别出来AuthToken类的属性和方法,如下所示:
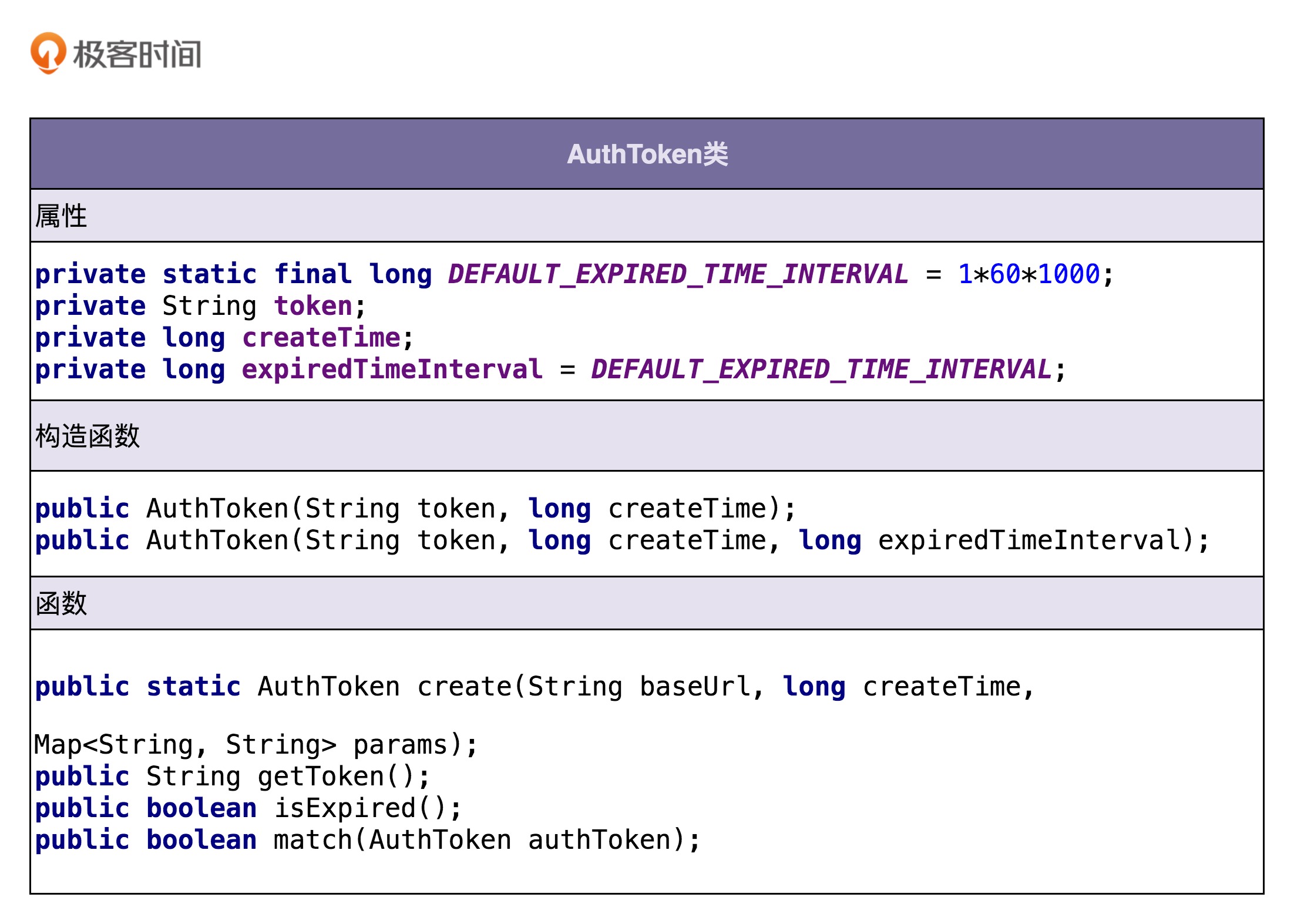
从上面的类图中,我们可以发现这样三个小细节。
- 第一个细节:并不是所有出现的名词都被定义为类的属性,比如URL、AppID、密码、时间戳这几个名词,我们把它作为了方法的参数。
- 第二个细节:我们还需要挖掘一些没有出现在功能点描述中属性,比如createTime,expireTimeInterval,它们用在isExpired()函数中,用来判定token是否过期。
- 第三个细节:我们还给AUthToken类添加了一个功能点描述中没有提到的方法getToken()。
第一个细节告诉我们,从业务模型上来说,不应该属于这个类的属性和方法,不应该被放到这个类里。比如URL、AppID这些信息,从业务模型上来说,不应该属于AuthToken,所以我们不应该放到这个类中。
第二、第三个细节告诉我们,在设计类具有哪些属性和方法的时候,不能单纯地依赖当下的需求,还要分析这个类从业务模型上来讲,理应具有哪些属性和方法。这样可以一方面保证类定义的完整性,另一方面不仅为当下的需求还为未来的需求做些准备。
Url类相关的功能点有两个:
- 将token、AppID、时间戳拼接到URL中,形成新的URL;
- 解析URL,得到token、AppID、时间戳等信息。
虽然需求描述中,我们都是以URL来代指接口请求,但是,接口请求并不一定是以URL的形式来表达,还有可能是Dubbo、RPC等其他形式。为了让这个类更加通用,命名更加贴切,我们接下来把它命名为ApiRequest。下面是我根据功能点描述设计的ApiRequest类。
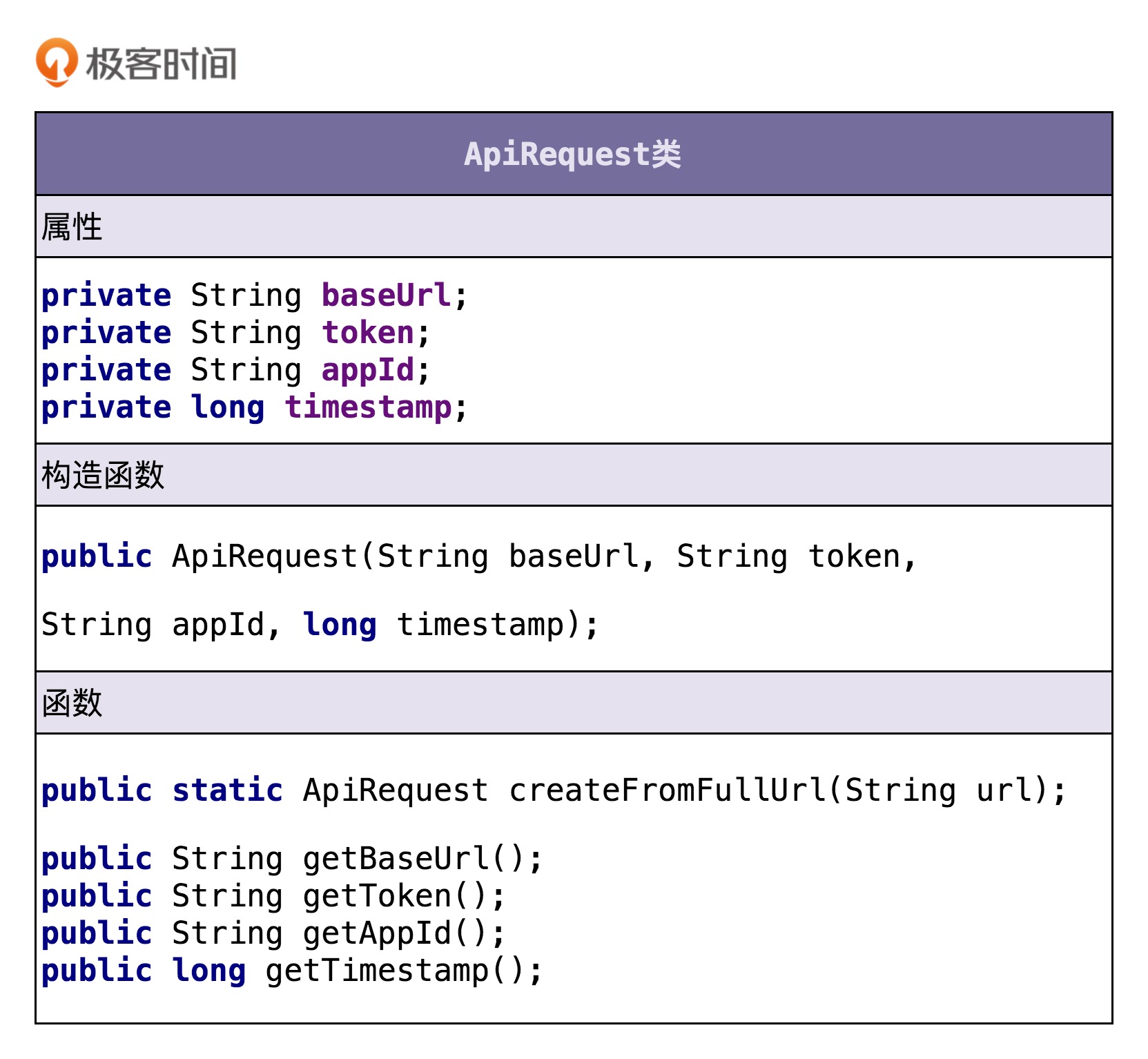
CredentialStorage类相关的功能点有一个:
- 从存储中取出AppID和对应的密码。
CredentialStorage类非常简单,类图如下所示。为了做到抽象封装具体的存储方式,我们将CredentialStorage设计成了接口,基于接口而非具体的实现编程。

3.定义类与类之间的交互关系
类与类之间都有哪些交互关系呢?UML统一建模语言中定义了六种类之间的关系。它们分别是:泛化、实现、关联、聚合、组合、依赖。关系比较多,而且有些还比较相近,比如聚合和组合,接下来我就注意讲解一下。
泛化(Generalization)可以简单理解为继承关系。
实现(Realization)一般是指接口和实现类之间的关系。
聚合(Aggregation)是一种包含关系,A类对象包含B类对象,B类对象的声明周期可以不依赖A类对象的生命周期,也就是说可以单独销毁A类对象而不影响B对象,比如课程与学生之间的关系。
组合(Composition)也是一种包含关系。A类对象包含B类对象,B类对象的生命周期依赖A类对象的生命周期,B类对象不可单独存在,比如鸟与翅膀之间的关系。
关联(Association)是一种非常弱的关系,包含聚合、组合两种关系。具体到代码层面,如果B类对象是A类的成员变量,那B类和A类就是关联关系。
依赖(Dependency)是一种比关联关系更加弱的关系,包含关联关系。不管是B类对象是A类对象的成员变量,还是A类对象的方法使用B列对象作为参数或者返回值、局部变量,只要B类对象和A类对象有任何使用关系,我们都称它们有依赖关系。
我从更加贴近编程的角度,对类与类之间的关系做了调整,只保留了四个关系:泛化、实现、组合、依赖,这样你掌握起来会更加容易。
其中,泛化、实现、依赖的定义不变,组合关系替代UML中组合、聚合、关联三个概念,也就相当于重新命名关联关系为组合关系,并且不再区分UML中的组合和聚合两个概念。之所以这样重新命名,是为了跟我们前面讲的“多用组合少用继承”设计原则中的“组合”统一含义。只要B类对象是A类对象的成员变量,那我们就称,A类跟B类是组合关系。
理论的东西讲完了,让我们来看一下,刚刚我们定义的类之间都有哪些关系呢?因为目前只有三个核心的类,所以只用到了实现关系,也即CredentialStorage和MysqlCredentialStorage之间的关系。
如何对接口鉴权这样一个功能开发做面向对象分析?
面向对象分析(OOA)、面向对象设计(OOD)、面向对象编程(OOP),是面向对象开发的三个主要环节。在前面的章节中,我对三者的讲解比较偏理论、偏概括性,目的是让你先有一个宏观的了解,知道什么是OOA、OOD、OOP。不过,光知道”是什么“是不够的,我们更重要的还是要知道”如何做“,也就是,如何进行面向对象分析、设计与编程。
在过往的工作中,我发现,很多工程是,特别是初级工程师,本身没有太多的项目敬艳艳,或者参与的项目都是基于开发框架填写CRUD模板式的代码,导致分析、设计能力比较欠缺。当他们拿到一个比较笼统的开发需求的时候,往往不知道从何下手。
对于”如何做需求分析,如何做职责划分?需要定义哪些类?每个类应该具有哪些属性、方法?类与类之间该如何交互?如何组装类成一个可执行的程序?“等等诸多问题,要有清晰的思路,最好利用成熟的设计原则、思想或者设计模式,开发出具有高内聚低耦合、易扩展、易读等优秀特性的代码了。
所以打算结合一个真实的开发案例,从基础的需求分析、职责划分、类的定义、交互、组装运行讲起,将最基础的面向对象分析、设计、编程的套路讲清楚,为后面学习设计原则、设计模式打好基础。
案例介绍和难点剖析
假设,你正在参与开发一个微服务。微服务通过HTTP协议暴露接口给其他系统调用,说直白点就是,其他系统通过URL来调用微服务的接口。有一天,你的leader找到你说,”为了保证接口调用的安全性,我们希望设计实现一个接口调用鉴权功能,只有经过认证之后的系统才能调我们的接口,没有认证过的系统调用我们的接口会被拒绝。我希望由你来负责这个任务的开发,争取尽快上线。“
leader丢下这句话就走了。这个时候,你该如何来做呢?有没有脑子里一团浆糊,一时间无从下手的感觉呢?为什么会有这种感觉呢?我个人觉得主要有下面两点原因。
1.需求不明确
leader给到的需求过于模糊、笼统,不够具体、细化,离落地到设计、编码还有一定的距离。而人的大脑不善于思考这种过于抽象的问题。这也是真实的软件开发区别于应试教育的地方。应试教育中的考试题目,一般都是一个非常具体的问题,我们去解答就好了。而真实的软件开发中,需求几乎都不是很明确。
我们前面讲过,面向对象分析主要的分析对象是”需求“,因此,面向对象分析可以粗略地看成”需求分析“。实际上,不管是需求分析还是面向对象分析,我们首先要做的都是将笼统的需求细化到足够清晰、可执行。我们需要通过沟通、挖掘、分析、假设、梳理,搞清楚具体的需求有哪些,哪些是现在要做的,哪些是未来可能要做的,哪些是不同考虑做的。
2.缺少锻炼
相比单纯的业务CRUD开发,鉴权这个开发任务,要更有难度。鉴权作为一个跟具体业务无关的功能,我们完全可以把它开发成一个独立的框架,集成到很多业务系统中。而作为被很多系统复用的通用框架,比起普通的业务代码,我们对框架的代码质量要求要更高。
开发这样通用的框架,对工程师的需求分析能力、设计能力、编码能力,甚至逻辑思维能力的要求,都是比较高的。如果你平时做的都是简单的CRUD业务开发,那这方面的锻炼肯定不会很多,所以,一旦遇到这种开发需求,很容易因为缺少锻炼,脑子放空,不知道从何入手,完全没有思路。
对案例进行需求分析
实际上,需求分析的工作很琐碎,也没有太多固定章法可寻,所以,我不打算很牵强的罗列那些听着有用、实际没用的方法论,而是希望通过鉴权这个例子,来给你展示一下,面对需求分析的时候,我的完整的思考路径是什么样的。希望你能自己去体会,举一反三的类比应用到其他项目的需求分析中。
尽管针对框架、组件、类库等非业务系统的开发,我们一定要有组件化意识、框架意识、抽象意识,开发出来的东西要足够通用,不能局限于单一的某个业务需求,但这并不代表我们就可以脱离具体的应用场景,闷头拍脑袋做需求分析。多跟业务团队聊聊天,甚至自己去参与几个业务系统的开发,只有这样,我们才能真正知道业务系统的痛点,才能分析出最优价值的需求。不过,针对鉴权这一功能的开发,最大的需求方还是我们自己,所以,我们也可以先从满足我们自己系统的需求开始,然后再迭代优化。
现在,我们来看一下,针对鉴权这个功能的开发,我们该如何做需求分析?
实际上,这跟做算法题类似,先从最简单的方案想起,然后再优化。所以,我把整个的分析过程分了循序渐进的四轮。每一轮都是对上一轮的迭代优化,最后形成一个可执行、可落地的需求列表。
1.第一轮基础分析
对于如何做鉴权这样一个问题,最简单的解决方案就是,通过用户名加密码来做认证。我们给每个允许访问我们服务的调用方,派发一个应用名(或者叫应用ID、AppID)和一个对应的密码(或者叫密钥)。调用方每次进行接口请求的时候,都携带自己的AppID和密码。微服务在接收到接口调用请求之后,会解析出AppID和密码,跟存储在微服务端的AppID和密码进行比对。如果一致,说明认证成功,则允许接口调用请求;否则,就拒绝接口调用请求。
2.第二轮分析优化
不过,这样的验证方式,每次都要明文传输密码。密码很容易被截获,是不安全的。那如果我们借助加密算法(比如SHA),对密码进行加密之后,再传递到微服务端验证,是不是就可以了呢?实际上,这样也是不安全的,因为加密之后的密码及AppID,照样可以被未认证系统(或者说黑客)接货,未认证系统可以携带这个加密之后的密码以及对应的AppID,伪装成已认证系统来访问我们的接口。这就是典型的"重放攻击"。
提出问题,然后再解决问题,是一个非常好的迭代优化方法。对于刚刚这个问题,我们可以借助OAuth的验证思路来解决。调用方将请求接口的URL跟AppID、密码拼接在一起,然后进行加密,生成一个token。调用方在进行接口请求的时候,将这个token及AppID,随URL一块传递给为服务端。为服务端接收到这些数据之后,根据AppID从数据库中取出对应的密码,并通过同样的token生成算法,生成另外一个token。用这个新生成的token跟调用方传递过来的token对比。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求。
这个方案稍微有点复杂,我画了一张示例图,来帮你理解整个流程。

3.第三轮分析优化
不过,这样的设计仍然存在重放攻击的风险,还是不够安全。每个URL拼接上AppID。密码生成的token都是固定给的。未认证系统截获URL、token和AppID之后,还是可以通过重放攻击的方式,伪装成认证系统,调用这个URL对应的接口。
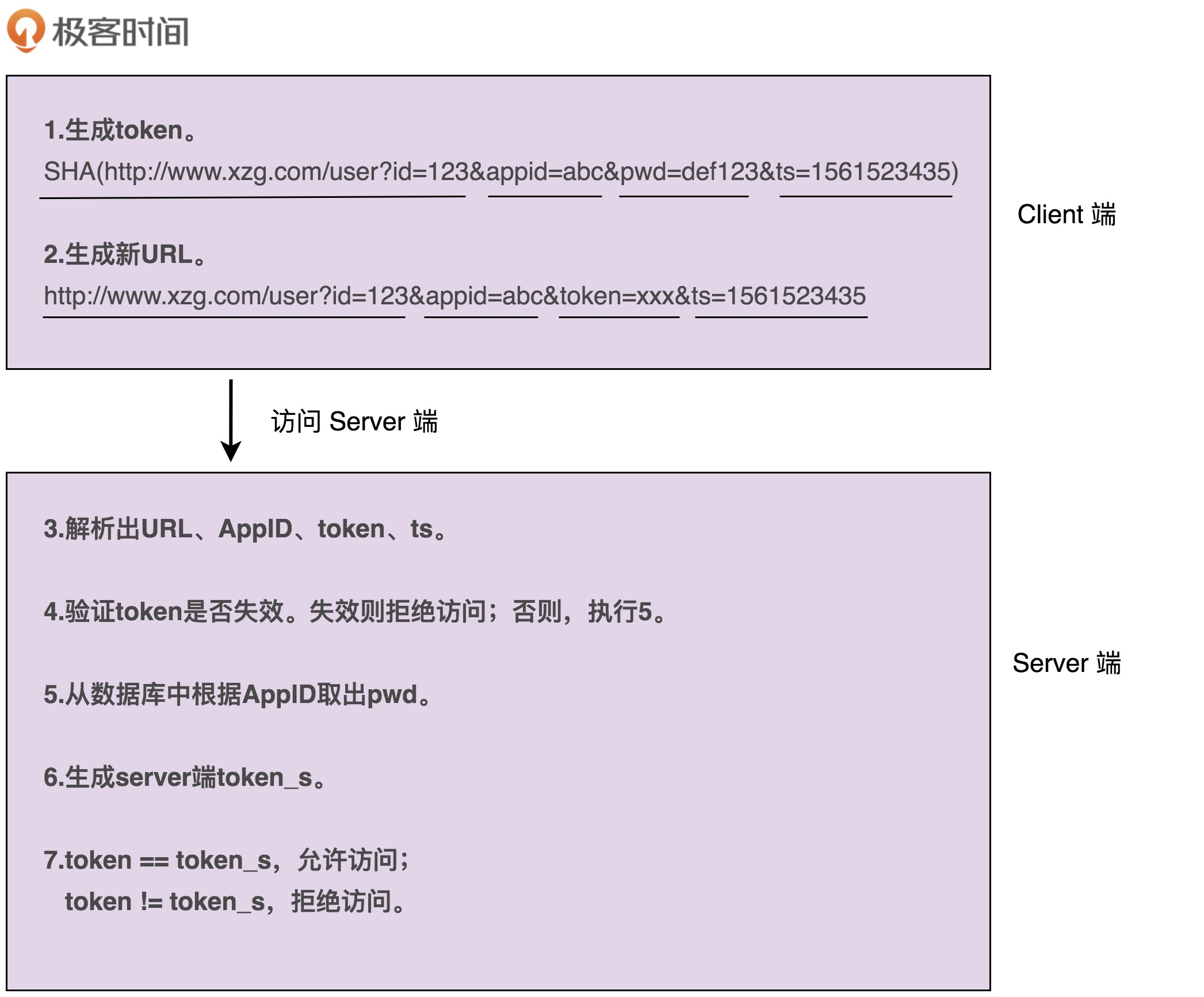
为了解决这个问题,我们可以进一步优化token生成算法,引入一个随机变量,让每次接口请求生成的token都不一样。我们可以选择时间戳作为随机变量。原来的token是对URL、AppID、密码三者进行加密生成的,现在我们将URL、AppID、密码、时间戳四者进行加密生成token。调用方在进行接口请求的时候,将token、AppID、时间戳,随URL一并传递给微服务端。
微服务端在收到这些数据之后,会验证当前时间跟传递过来的时间戳,是否在一定的时间窗口内(比如一分钟)。如果超过一分钟,会判定token过期,拒绝接口请求。如果没有超过一分钟,则说明token没有过期,就再通过同样的token生成算法,在服务端生成新的token,与调用方传递过来的token比对,看是否一致。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求。
优化之后的认证流程如下图所示。
4.第四轮分析优化
不过,你可能会说,这样还是不够安全啊。未认证系统还是可以在这一分钟的token失效窗口内,通过截获请求、重放请求,来调用我们的接口啊!(反解密出token算法,解析出时间戳,不停的用此时的时间戳替换,然后重放攻击)
你说的没错。不过,攻与防之间,本来就没有绝对的安全。我们能做的就是,尽量提高攻击的成本。这个方案虽然还有漏洞,但是实现起来足够简单,而且不会过度影响接口本身的性能(比如响应时间)。所以,权衡安全性、开发成本、对系统性能的影响,这个方案算是比较折中、比较合理的了。
实际上,还有一个细节我们没有考虑到,那就是,如何在微服务度存储每个授权调用方的AppID和密码。当然,这个问题并不难。最容易想到的方案就是存储到数据库里,比如MySQL。不过,开发像鉴权这样的非业务功能,最好不要与具体的第三方系统有过度的耦合。
针对AppID和密码的存储,我们最好能灵活的支持各种不同的存储方式,比如ZooKeeper、本地配置文件、自研配置中心、MySQL、Redis等。我们不一定针对每种存储方式都去做代码实现,但起码要留点扩展点,保证系统有足够的灵活性和扩展性,能够在我们切换存储方式的时候,尽可能第减少代码的改动。
5.最终确定需求
到此,需求已经足够细化和具体了。现在,我们按照鉴权的流程,对需求再重新描述一下。如果你熟悉UML,也可以用时序图、流程图来描述。不过,用什么描述不是重点,描述清楚才是最终要的。考虑到在接下来的面向对象设计环节中,我会基于文字版本的需求描述,来进行类、属性、方法、交互等的设计,所以,这里我给出的最终需求描述是文字版本的。
- 调用方进行接口请求的时候,将URL、AppID、密码、时间戳拼接在一起,通过加密算法生成token,并且将token、AppID、时间戳拼接在URL中,一并发送到微服务端。
- 微服务端在接收到调用方的接口请求之后,从请求中拆接触token、AppID、时间戳。
- 微服务端首先检查传递过来的时间戳跟当前时间,是否在token失效时间窗口内。如果已经超过失效时间,那就算接口调用鉴权失败,拒绝接口调用请求。
- 如果token验证没有过期失效,微服务端再从自己的存储中,取出AppID对应的密码,通过同样的token生成算法,生成另外一个token,与调用方传递过来的token进行匹配:如果一致,则鉴权成功,允许接口调用,否则就拒绝接口调用。
这就是我们需求分析的整个思考过程,从最粗糙、最模糊的需求开始,通过”提出问题-解决问题“的方式,循序渐进的进行优化,最后得到一个足够清晰、可落地的需求描述。
重点回顾
针对框架、类库、组件等非业务系统的开发,其中一个比较大的难点就是,需求一般都比较抽象、模糊,需要你自己去挖掘,做合理取舍、权衡、假设,把抽象的问题具象化,最终产生清晰的、可落地的需求定义。需求定义是否清晰、合理,直接影响了后续的设计、编码实现是否顺畅。所以,作为程序员,你一定不要只关心设计与实现,前期的需求分析同等重要。
需求分析的过程实际上是一个不断迭代优化的过程。我们不要试图以下就能给出一个完美的解决方案,而是先给出一个粗糙的、基础的方案,有一个迭代的基础,然后再慢慢优化,这样一个思考过程能让我们拜托无从下手的窘境。
如何利用基于充血模型的DDD开发一个虚拟钱包系统?
转载
文章转载自极客时间王争老师的设计模式之美专栏
钱包业务背景介绍
很多具有支付、购买功能的应用(比如淘宝、滴滴出行、极客时间等)都支持钱包的功能。应用为每个用户开设一个系统内的虚拟钱包账户,支持用户重置、提现、支付、冻结、透支、转赠、查询账户余额、查询交易流水等操作。下图是一张典型的钱包功能界面,你可以直观的感受一下。
一般来讲,每个虚拟钱包账户都会对应用户的一个真实的支付账户,有可能是银行卡账户,也有可能是三方支付账户(比如支付宝、微信钱包)。为了方便后续的讲解,我们限定钱包暂时只支持充值、提现、支付、查询余额、查询交易流水这五个核心的功能,其他比如冻结、透支、转赠等不常用的功能,我们暂不考虑。为了让你理解这五个核心功能是如何工作的,接下来,我们来一块儿看下它们的业务实现流程。
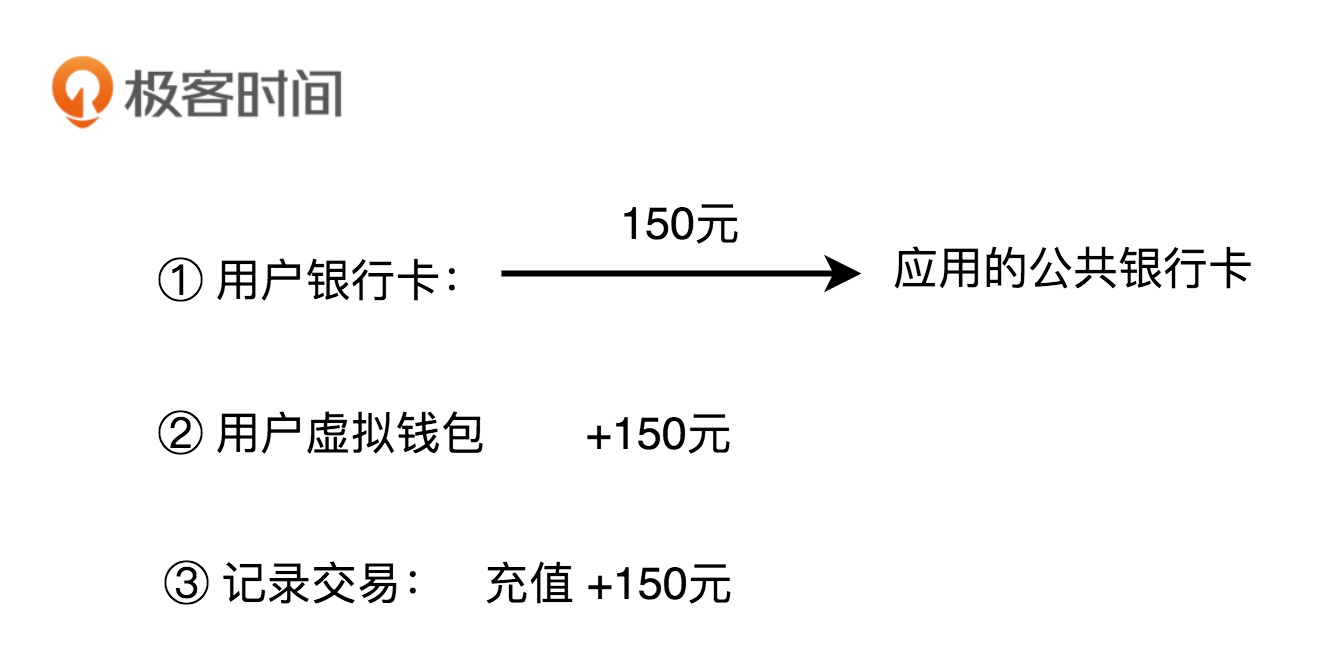
1.充值
用户通过三方支付渠道,把自己银行卡账户内的钱,充值到虚拟钱包账号中。这整个过程,我们可以分解为三个主要的操作流程:第一个操作是从用户的银行卡账户转账到应用的公共银行卡账户;第二个操作是将用户的充值金额添加到虚拟钱包余额上;第三个操作是记录刚刚这笔交易流水。
2.支付
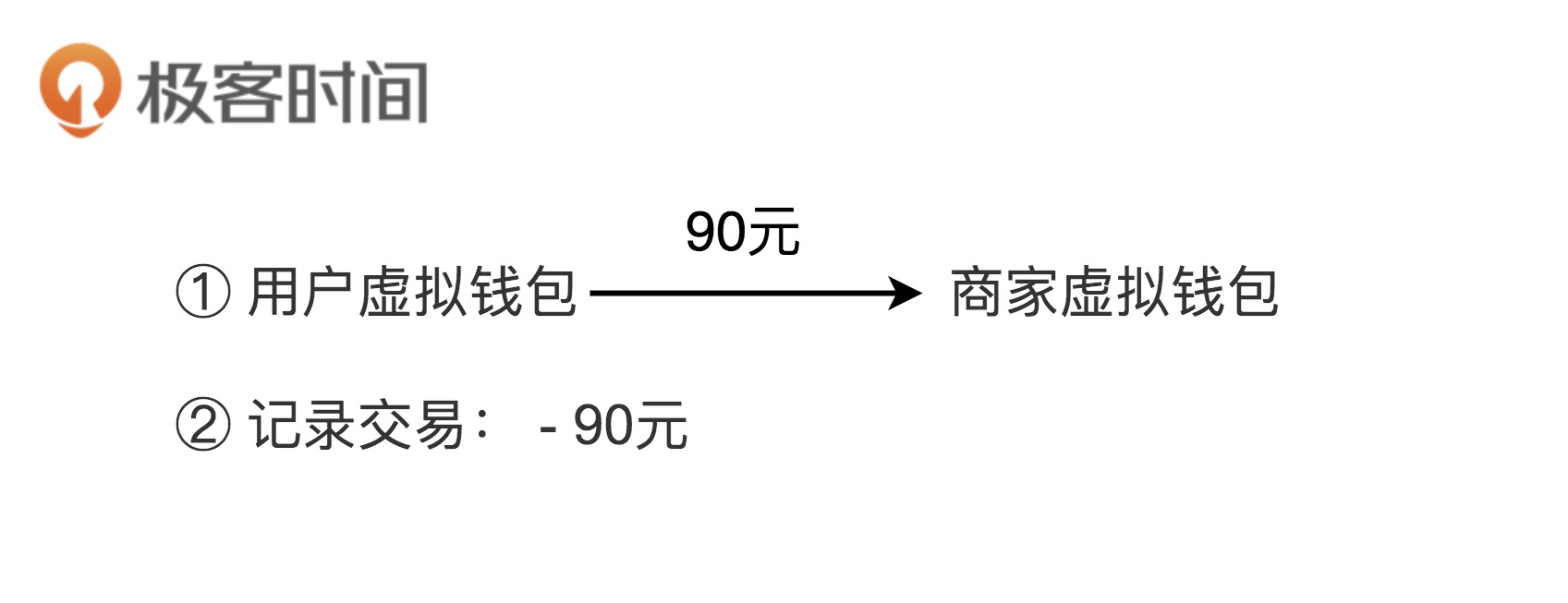
用户用钱包内的余额,支付购买应用内的商品。实际上,支付的过程就是一个转账的过程,从用户的虚拟钱包账户划钱到商家的虚拟钱包账户上。除此之外,我们也需要记录这笔支付的交易流水信息。
3.提现
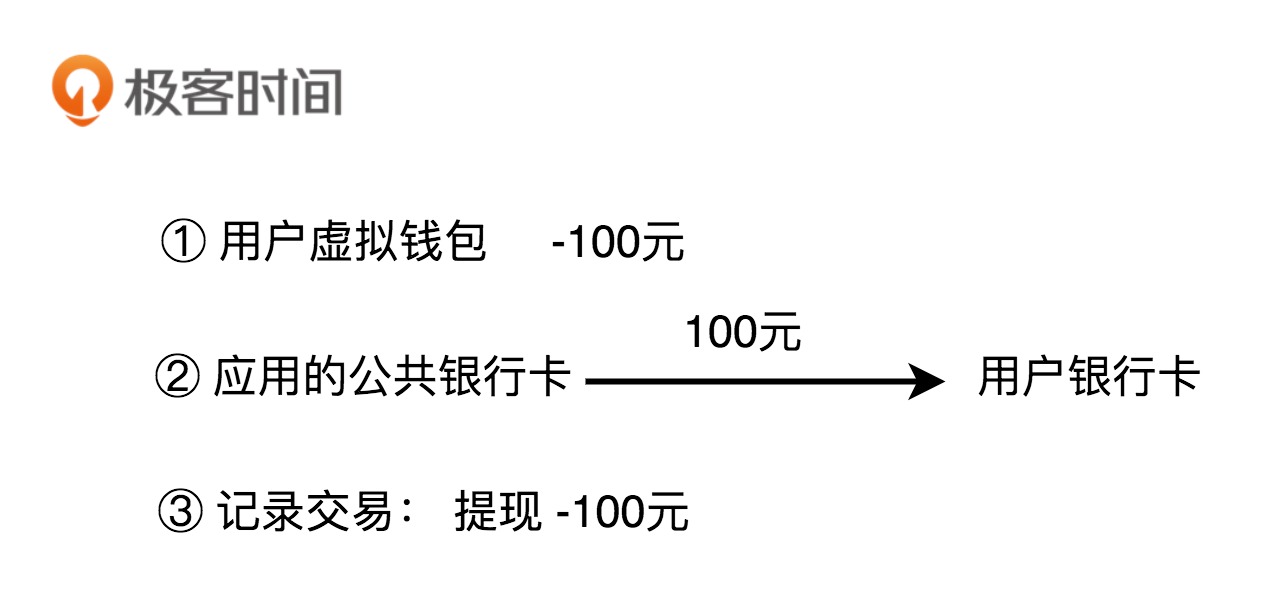
除了充值、支付之外,用户还可以将虚拟钱包中的余额,提现到自己的银行卡中。这个过程实际上就是扣减用户虚拟钱包中的余额,并且触发真正的银行转账操作,从应用的公共银行账户转钱到用户的银行账户。同样,我们也需要记录这笔提现的交易流水信息。
4.查询余额
查询余额功能比较简单,我们看一下虚拟钱包中的余额数字即可。
5.查询交易流水
查询交易流水也比较简单。我们只支持三种类型的交易流水:充值、支付、提现。在用户充值、支付、提现的时候,我们会记录相应的交易信息。在需要查询的时候,我们只需要将之前记录的交易流水,按照时间、类型等条件过滤之后,显示出来即可。
钱包系统的设计思路
根据刚刚讲的业务实现流程和数据流转图,我们可以把整个钱包系统的业务划分为两部分,其中一部分单纯跟应用内的虚拟钱包账户打交道,另一部分单纯跟银行账户打交道。我们基于这样一个业务划分,给系统解耦,将整个钱包系统拆分为两个子系统:虚拟钱包系统和三方支付系统。
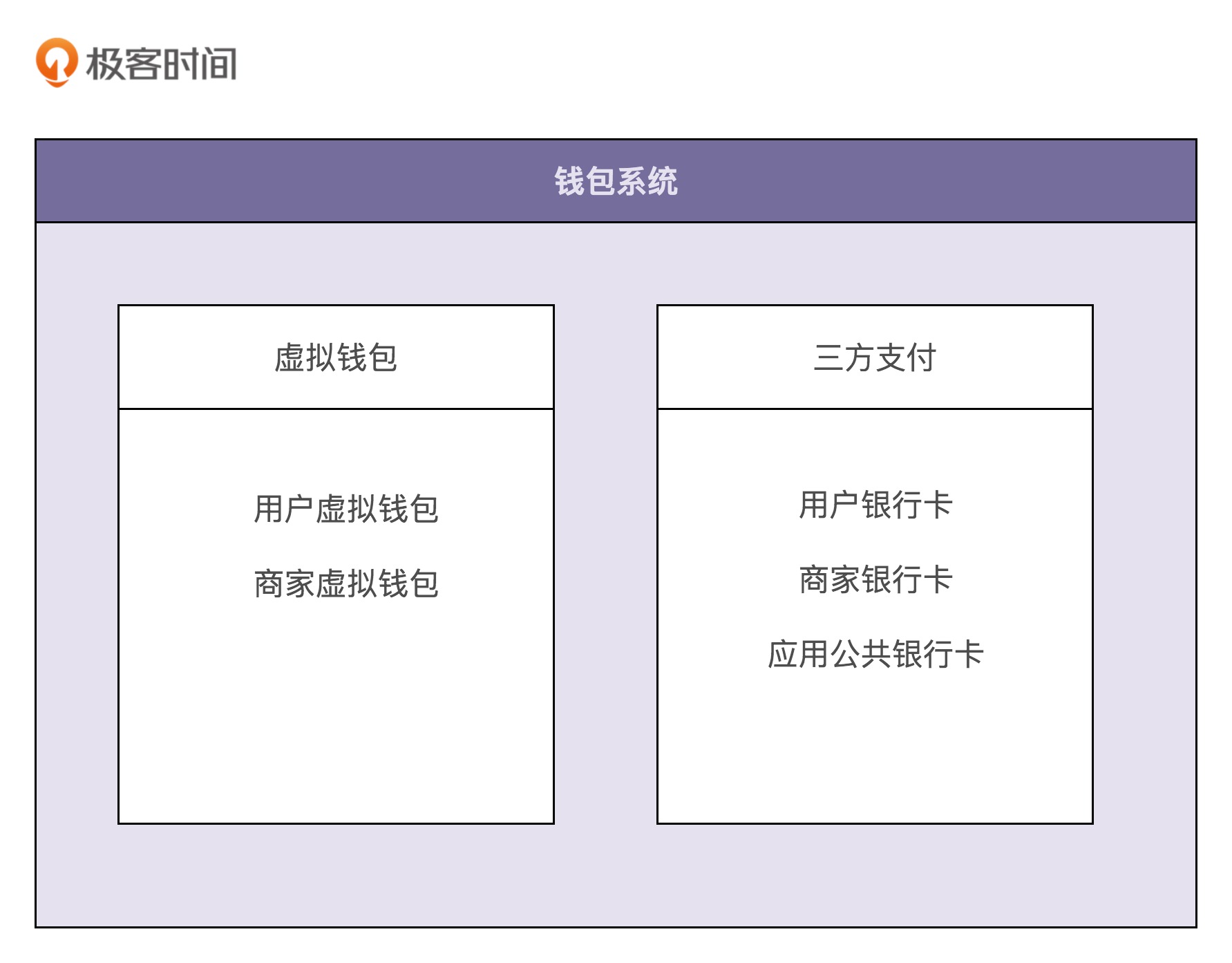
为了能在有限的篇幅内,将今天的内容讲透彻,我们接下来只聚焦于虚拟钱包系统的设计与实现。对于三方支付系统以及整个钱包系统的设计与实现,不作讲解,可以自己思考一下。
现在我们来看下,如果要支持钱包的这五个核心功能,虚拟钱包系统需要对应实现哪些操作。我画了一张图,列出了这五个功能都会对应虚拟钱包的哪些操作。注意,交易流水的记录和查询,我暂时在图中打了个问号,那是因为这块比较特殊,待会再讲。
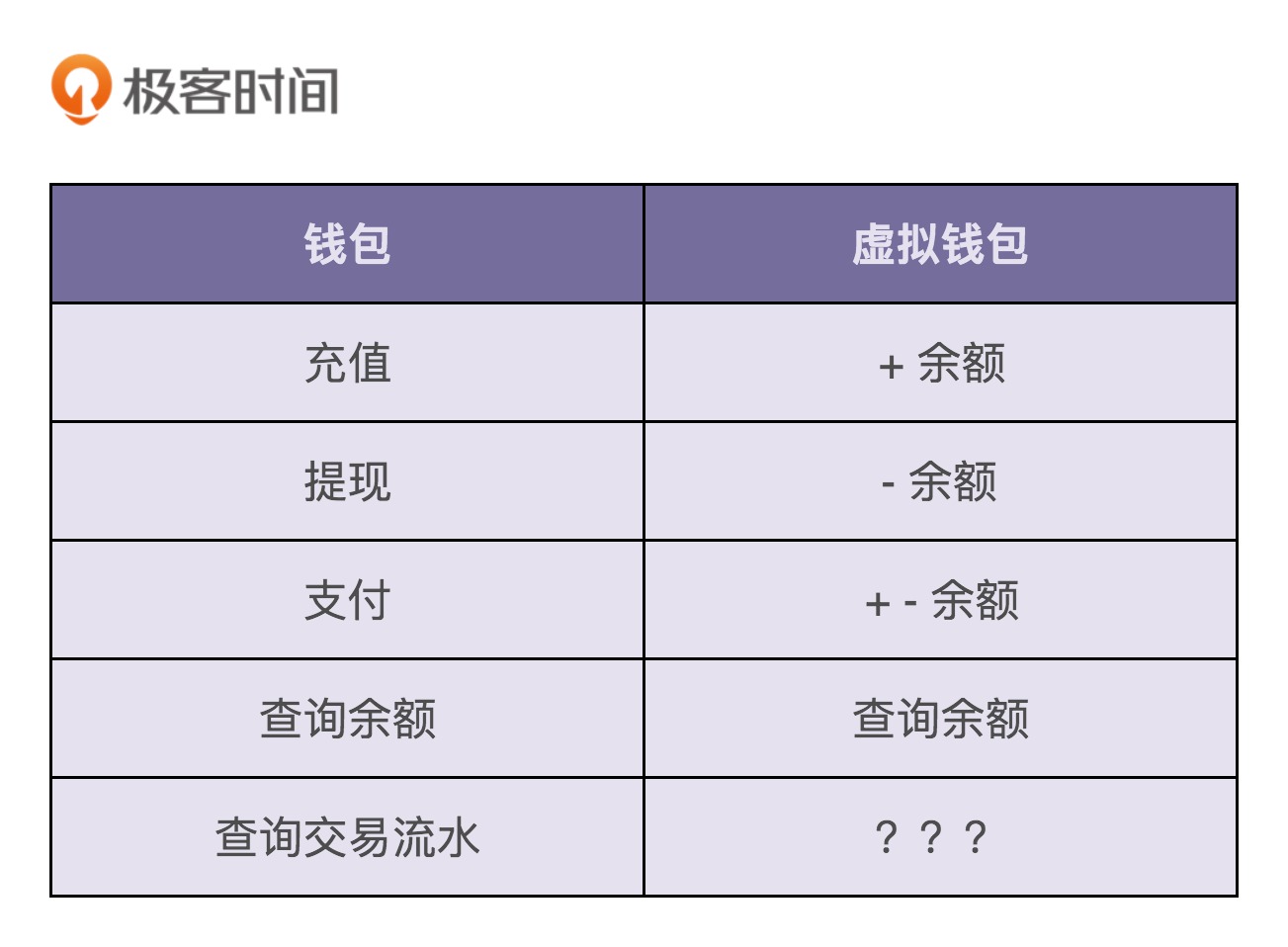
从图中我们可以看出,虚拟钱包系统要支持的操作非常简单,就是余额的加加减减。其中,充值、提现、查询余额三个功能,只涉及一个账户余额的加减操作,而支付功能涉及两个账户的余额加减操:一个账户减余额,另一个账户加余额。
现在,我们再来看一下图中问号的那部分,也就是交易流水该如何记录和查询?我们先来看一下,交易流水都需要包含哪些信息。我觉得下面这几个信息是必须包含的。
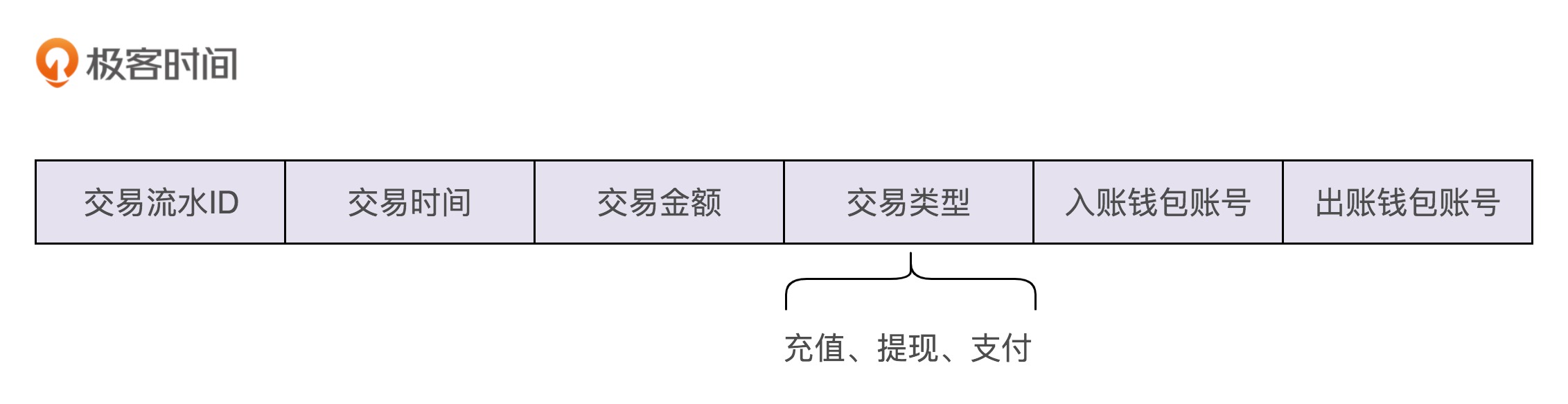
从图中我们可以发现,交易流水的数据格式包含两个钱包账号,一个是入账钱包账号,一个是出账钱包账号。为什么要有两个账号信息呢?这主要是为了兼容支付这种涉及两个账户的交易类型。不过,对于充值、提现这两种交易类型来说,我们只需要记录一个钱包账户信息就够了,所以,这样的交易流水数据格式的涉及稍微有点浪费存储空间。
实际上,我们还有另外一种交易流水数据格式的设计思路,可以解决这个问题。我们把”支付“这个交易类型,拆为两个子类型:支付和被支付。支付单纯表示出账,余额扣减,被支付单纯表示入账,余额增加。这样我们在设计交易流水数据格式的时候,只需要记录一个账户信息即可。我画了一张两种交易流水数据格式的对比图,你可以对比着看一下。
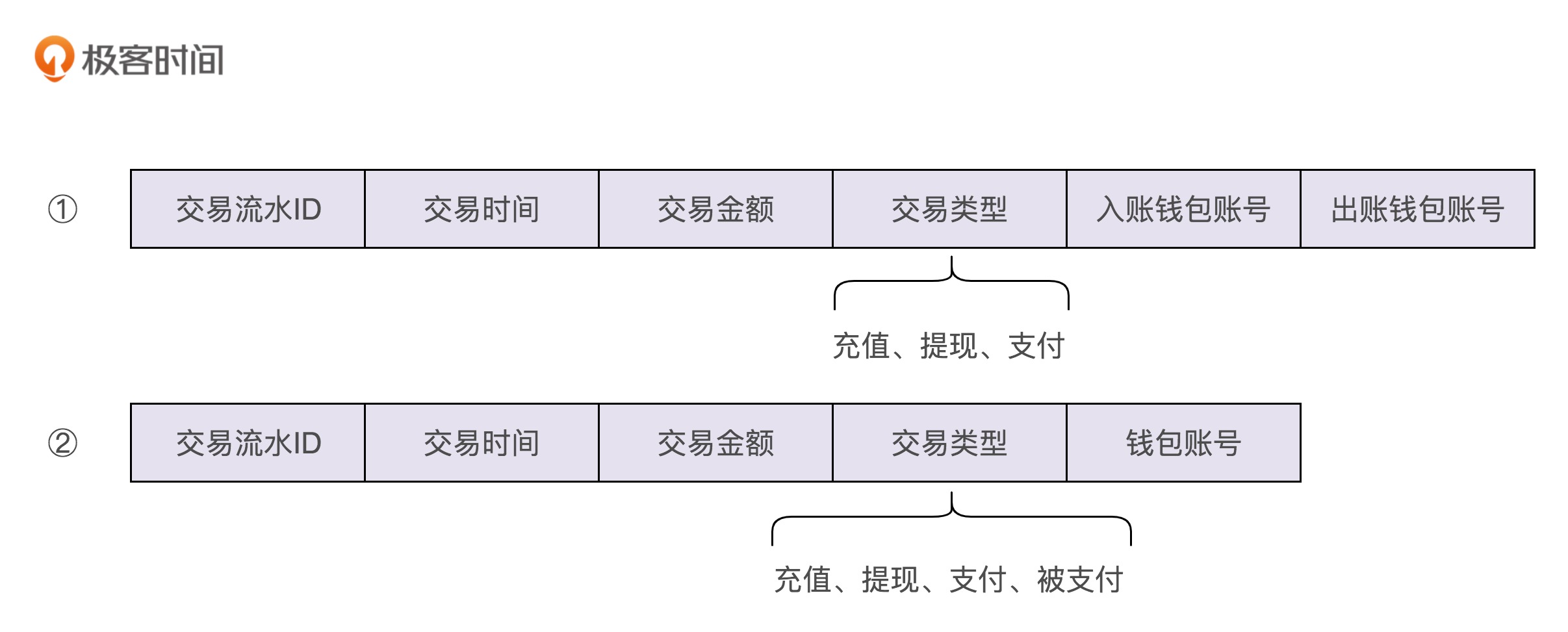
那以上两种交易流水数据格式的设计思路,你觉得哪一个更好呢?
答案是第一种设计思路更好些。因为交易流水有两个功能:一个是业务功能,比如,提供用户查询交易流水信息;另一个是非业务功能,保证数据的一致性。这里主要是指支付操作数据的一致性。
支付实际上就是一个转账的操作,在一个账户上加上一定的金额,在另一个账户上减去相应的金额。我们需要保证加金额和减金额这两个操作,要么都成功,要么都失败。如果一个成功,一个失败,就会导致数据的不一致,一个账户明明减掉了钱,理你个一个账户却没有收到钱。
保证数据一致性的方法有很多,比如依赖数据库事务的原子性,将两个操作放在同一个事务中执行。但是,这样的做法不够灵活,因为我们有可能做了分库分表,支付涉及的两个账户可能存储在不同的库中,无法直接利用数据库本身的事务特性,在一个事务中执行两个账户的操作。当然,我们还有一些支持分布式事务的开源框架,但是,为了保证数据的强一致性,它们的实现逻辑一般都比较复杂、本身的性能也不高,会影响业务的执行时间。所以,更加权衡的一种做法就是,不保证数据的强一致性,只实现数据的最终一致性,也就是我们刚刚提到的交易流水要实现的非业务功能。
对于支付这样的类似转账的操作,我们在操作两个钱包账户余额之前,先记录交易流水,并且标记为"待执行",当两个钱包的加减金额都完成之后,我们再回过头来,将交易流水标记为"成功"。在给两个钱包加减金额的过程中,如果有任意一个操作失败,我们就将交易记录的状态标记为"失败"。我们通过后台补漏Job,拉去状态为"失败"或者长时间处于"待执行"状态的交易记录,重新执行或者人工介入处理。(两阶段提交,根据流水可以反推余额,反之则不可以)
如果选择第二种交易流水的设计思路,使用两条交易流水来记录支付操作,那记录两条交易流水本身又存在数据的一致性问题,有可能入账的交易流水记录成功,出账的交易流水信息记录失败。所以,权衡利弊,我们选择第一种稍微有些冗余的数据格式设计思路。
现在,我们在思考这样一个问题:充值、提现、支付这些业务交易类型,是否应该让虚拟钱包系统感知?换句话说,我们是否应该在虚拟钱包系统的交易流水中记录这三种类型?
答案是否定的。虚拟钱包系统不应该感知具体的业务交易类型。我们前面讲到,虚拟钱包支持的操作,仅仅是余额的加加减减操作,不涉及复杂业务概念,职责单一、功能通用。如果耦合太多业务概念到里面,势必影响系统的通用性,而且还会导致系统越做越复杂。因此,我们不希望将充值、支付、体现这样的业务概念添加到虚拟钱包系统中。
但是,如果我们不在虚拟钱包系统的交易流水中记录交易类型,那在用户查询交易流水的时候,如何显示每条交易流水的交易类型呢?
从系统设计的角度,我们不应该在虚拟钱包系统的交易流水中记录交易类型。从产品需求的角度来说,我们又必须记录交易流水的交易烈性。听起来比较矛盾,这个问题该如何解决呢?
我们可以通过记录两条交易流水信息的方式来解决。我们前面讲到,整个钱包系统分为两个子系统,上层钱包系统的实现,依赖底层虚拟钱包系统和三方支付系统。对于钱包系统来说,它可以感知充值、支付、提现等业务概念,所以,我们在钱包系统这一层额外在记录一条包含交易类型的交易流水信息,而在底层的虚拟钱包系统中国基路不包含交易类型的交易流水信息。
为了让你更好地理解刚刚的设计思路,我画了一张图,你可以对比着我的讲解一块儿来看。

我们通过查询上层钱包系统的交易流水信息,去满足用户查询交易流水的功能需求,而虚拟钱包中的交易流水就只是用来解决数据一致性问题。实际上,它的作用还有很多,比如用来对账等。限于篇幅,这里我们就不展开讲了。
整个虚拟钱包的设计思路到此讲完了。接下来,我们来看一下,如何分别用基于贫血模型的传统开发模式和基于充血模型的DDD开发模式,来实现这样一个虚拟钱包系统?
基于贫血模型的传统开发模式
如果有一定的Web项目开发经验,并且听明白了我刚刚讲的设计思路,利用基于贫血模型的传统开发模式来实现这样一个系统,应该是一件挺简单的事情。
这是一个典型的Web后端项目的三层结构。其中,COntroller和VO负责暴露接口,具体的代码实现如下所示。注意,Controller中,接口实现比较简单,主要就是调用Service的方法,所以,我省略了具体的代码实现。
1 | public class VirtualWalletController { |
Service和BO负责核心业务逻辑,Repository和Entity负责数据存取。Repository这一层的代码实现比较简单,不是我们讲解的重点,所以我也省略调了。Srvice层的代码如下所示。注意,这里我省略了一些不重要的校验代码,比如,对amount是否小于0、钱包是否存在的校验等等。
1 | public class VirtualWalletService { |
以上便是利用基于贫血模型的传统开发模式来实现的虚拟钱包系统。尽管我们对代码稍微做了简化,但整体的业务逻辑就是上面这样子。其中大部分代码逻辑都非常简单,最复杂的是Service中的transfer()转账函数。我们为了保证转账操作的数据一致性,添加了一些跟transaction相关的记录和状态更新的代码。
基于充血模型的DDD开发模式
在上一篇文章中,我们讲到,基于充血模型的DDD开发模式,跟基于贫血模型的传统开发模式的主要区别就在Service层,Controller层和Repository层的代码基本上相同。所以,我们重点看一下,Service层按照基于充血模型的DDD开发模式该如何来实现。
在这种开发模式下,我们把虚拟钱包VirtualWallet类设计成一个充血的Domain领域模型,并且将原来在Service类中的部分业务逻辑移动到VirtualWallet类中,让Service类的实现依赖VirtualWallet类。具体的代码实现如下所示:
1 | public class VirtualWallet { |
看了上面的代码,你可能会说,领域模型VirtualWallet类很单薄,包含的业务逻辑很简单。相对于原来的贫血模型的设计思路,这种充血模型的设计思路,貌似并没有太大优势。你说得没错!这也是大部分业务系统都使用基于贫血模型开发的原因。不过,如果虚拟钱包系统需要支持更复杂的业务逻辑,那充血模型的优势就显现出来了。比如,我们要支持透支一定额度和冻结部分余额的功能。这个时候,我们重新来看一下VirtualWallet类的实现代码。
1 | public class VirtualWallet { |
领域模型VirtualWallet类添加了简单的冻结和透支逻辑之后,功能看起来就丰富了很多,代码也没那么单薄了。如果功能继续演进,我们可以增加更加细化的冻结策略、透支策略、支持钱包账号(VirtualWallet id字段)自动生成的逻辑(不是通过构造函数境外不传入ID,而是通过分布式ID生成算法来自动生成ID)等等。VirtualWallet类的业务逻辑会变得越来越复杂,也就很值得设计成充血模型了。
辩证思考与灵活应用
对于虚拟钱包系统的设计与两种开发模式的代码实现,应该有一个比较清晰的了解了。不过,我觉得还有两个问题值得讨论一下。
第一个要讨论的问题是:在基于充血模型的DDD开发模式中,将业务逻辑移动到Domain中,Service类变得很薄,但在我们的代码设计与实现中,并没有完全将Service类去掉,这是为什么?或者说,Service类在这种情况下担当的职责是什么?哪些功能逻辑会放到Service类中?
区别于Domain的职责,Service类主要有下面这样几个职责。
Service类负责与Repository交流。在我的设计与代码实现中,VirtualWalletService类负责与Repository层打交道,调用Repository类的方法,获取数据库中的数据,转化成领域模型VirtualWallet,然后由领域模型VirtualWallet来完成业务逻辑,最后调用Repository类的方法,将数据存回数据库。
这我再稍微解释一下,之所以让VirtualWalletService类与Repository打交道,而不是让领域模型VirtualWallet与Repository打交道,那是因为我们想保持领域模型的独立性,不与任何其他层的代码(Repository层的代码)或开发框架(比如Spring、MaBatis)耦合在一起,将流程性的代码逻辑(比如从DB中取数据、映射数据)与领域模型的业务逻辑解耦,让领域模型更加可复用。
Service类负责跨领域模型的业务聚合功能。VirtualWalletService类中农的transfer()转张函数会涉及两个钱包的操作,因此这部分业务逻辑无法放到VirtualWallet类中,所以,我们暂且把转账业务放到VirtualWalletService类中了。当然,虽然功能演进,使得转账业务变得复杂起来之后,我们也可以将转账业务抽取出来,设计成一个独立的领域模型。
Service类负责一些非功能性及与三方系统交互的工作。比如幂等、事务、发邮件、发消息、记录日志、调用其他系统的RPC接口等,都可以放到Service类中。
第二个要讨论的问题是:在基于充血模型的DDD开发模式中,尽管Service层被改造成了充血模型,但是Controller层和Repository层还是贫血模型,是否有必要也进行充血领域建模呢?
答案是没有必要。Controller层主要负责接口的暴露,Repository层主要负责与数据库打交道,这两层包含的业务逻辑并不多,前面我们也提到了,如果业务逻辑比较简单,就没必要充血建模,即便设计成充血模型,类也非常单薄,看起来也很奇怪。
尽管这样的设计是一种面向过程的编程风格,但我们只要控制好面向过程编程风格的副作用,照样可以开发出优秀的软件。那这里的副作用怎么控制呢?
就拿Repository的Entity来说,即便它被设计成贫血模型,违反面向对象编程的封装特性,有被任意代码修改数据的风险,但Entity的生命周期是有限的。一般来讲,我们把它传递到Service层之后,就会转化成BO或者Domain来继续后面的业务逻辑。Entity的生命周期到此就结束了,所以也并不会被到处任意修改。
我们再来说说Controller层的VO。实际上VO是一种DTO(Data Transfer Object,数据传输对象)。它主要是作为接口的数据传输承载体,将数据发送给其他系统。从功能上来说,它理应不包含业务逻辑、只包含数据。所以,我们将它设计成贫血模型也是比较合理的。
重点回顾
基于充血模型的DDD开发模式跟基于贫血模型的传统开发模式相比,主要区别在Service层。在基于充血模型的开发模式下,我们将部分原来在Service类中的业务逻辑移动到了一个充血的Domain领域模型中,让Service类的实现依赖这个Domain类。
在基于充血模型的DDD开发模式下,Service类并不会完全移除,而是负责一些不适合放在Domain类中的功能。比如,负责与Repository层打交道。跨领域模型的业务聚合功能、幂等事务等非功能性的工作。
基于充血模型的DDD开发模式跟基于贫血模型的传统开发模式相比,Controller层和Repository层的代码基本上相同。这是因为,Repository层的Entity生命周期有限,Controller层的VO只是淡出您作为一种DTO。两部分的业务逻辑都不会太复杂。业务逻辑主要集中在Service层。所以,Repository层和Controller层继续沿用贫血模型的设计思路是没有问题的。
讨论
这两节课中对于 DDD 的讲解,都是我的个人主观看法,你可能会有不同看法。
业务开发常用的基于贫血模型的MVC架构违背OOP吗?
我们都知道,很多业务系统都是基于MVC三层架构来开发的。实际上,更确切点讲,这是一种基于贫血模型的MVC三层架构开发模式。
虽然这种开发模式已经成为标准的Web项目的开发模式,但它却违反了面向对象编程风格,是一种彻彻底底的面向过程的编程风格,因此而被有些人称为反模式。特别是领域驱动设计(Domain Driven Design,简称DDD)盛行之后,这种基于贫血模型的传统的开发模式就更加被人诟病。而基于充血模型的DDD开发模式越来越被人提倡。所以,我打算用两节课的时间,结合一个虚拟钱包系统的开发案例,带你彻底弄清楚这两种开发模式。
在正式进入到实战项目将截止前,我先带你搞清楚下面几个问题:
- 什么是贫血模型?什么是充血模型?
- 为什么说基于贫血模型的传统开发模式违反OOP?
- 基于贫血模型的传统开发模式既然违反OOP,那又为什么如此流行?
- 什么情况下我们应该考虑使用基于充血模型的DDD开发模式?
什么是基于贫血模型的传统开发模式?
我相信,对于大部分的后端开发工程师来说,MVC三层架构都不会陌生。不过,为了统一认识,还是回顾一下,什么是MVC三层架构。
MVC三层架构中的M表示Model,V表示View,C表示Controller。它将整个项目分成三层:展示层、逻辑层、数据层。MVC三层开发架构是一个比较笼统的分层方式,落实到具体的开发层面,很多项目也并不会100%遵从MVC固定的分层方式,而是会根据具体的项目需求,做适当的调整。
比如,现在很多Web或者App项目都是前后端分离的,后端负责暴露接口给前端调用。这种情况下,我们一般就将后端项目分为Repository层、Service层、Controller层、其中,Repository层负责数据访问,Service层负责业务逻辑,Controller层负责暴露接口。当然,这只是其中一种分层和命名方式。不同的项目、不同的团队,可能会对此有所调整。不过,万变不离其宗,只要是依赖数据库开发的Web项目,基本的分层思路都大差不差。
刚刚我们回顾了MVC三层开发架构。现在,我们再来看一下,什么是贫血模型?
不夸张的讲,据我了解,目前几乎所有的业务后端系统,都是基于贫血模型的。我举一个简单的例子来解释一下。
1 | // Controller + VO(View Object) |
我们平时开发Web后端项目的时候,基本上都是这么组织代码的。其中,UserEntity和UserRepository组成了数据访问层,UserBo和UserService组成了业务逻辑层,UserVo和UserController在这里属于接口层。
在代码中,我们可以发现,UserBo是一个纯粹的数据结构,只包含数据,不包含任何业务逻辑。业务逻辑集中在userService中。我们通过UserService来操作UserBo。换句话说,Service层的数据和业务逻辑,被分割为BO和Service两个类中。像UserBo这样,只包含数据,不包含业务逻辑的类,就叫做贫血模型(Anemic Domain Model)。同理,UserEntity、UserVo都是基于贫血模型设计的。这种贫血模型将数据与操作分离,破坏了面向对象的封装特性,是一种典型的面向过程的编程风格。
什么是基于充血模型的DDD开发模式?
刚刚我们讲了基于贫血模型的传统的开发模式。现在我们再讲一下,另外一种最近更加被推崇的开发模式:基于充血模型的DDD开发模式。
首先,我们先来看一下,什么是充血模型?
在贫血模型中,数据和业务逻辑被分割到不同的类中。充血模型(Rich Domain Model)正好相反,数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象的编程风格。
接下里,我们再来看一下,什么是领域驱动设计?
领域驱动设计,即DDD,主要是用来指导如何解耦业务系统,划分业务模块,定义业务领域模型及其交互。领域驱动设计这个概念并不新颖,早在2004年就被踢出了,到现在已经有十几年的历史了。不过。它被大众熟知,还是基于另一个概念的兴起,那就是微服务。
我们知道,除了监控、调用链追踪、API网关等服务治理系统的开发之外,微服务还有另外一个更加重要的工作,那就是针对公司的业务,合理地做微服务拆分。而领域驱动设计恰好就是用来指导划分服务的。所以,微服务加速了领域驱动设计的盛行。
不过,我个人觉得,领域驱动设计有点儿类似敏捷开发、SOA、PAAS 等概念,听起来很高大上,但实际上只值“五分钱”。即便你没有听说过领域驱动设计,对这个概念一无所知,只要你是在开发业务系统,也或多或少都在使用它。做好领域驱动设计的关键是,看你对自己所做业务的熟悉程度,而并不是对领域驱动设计这个概念本身的掌握程度。即便你对领域驱动搞得再清楚,但是对业务不熟悉,也并不一定能做出合理的领域设计。所以,不要把领域驱动设计当银弹,不要花太多的时间去过度地研究它
实际上,基于充血模型的DDD开发模式实现的代码,也是按照MVC三层架构分层的。Controller层还是负责暴露接口,Repository层还是负责数据存取,Service层负责核心业务逻辑。它跟基于贫血模型的传统开发模式的区别主要在Service层。
在基于贫血模型的传统开发模式中,Service层包含Service类和BO类两部分,BO是贫血模型,只包含数据,不包含具体的业务逻辑。业务逻辑集中在Service类中。在基于充血模型的DDD开发模式中,Service层包含Service类和Domain类两部分。Domain就相当于贫血模型中的BO。不过,Domain与BO的区别在于它是基于充血模型开发的,既包含数据,也包含业务逻辑。而Service类变得非常单薄。总结一下的话就是,基于贫血模型的传统的开发模式,重Service轻BO;基于充血模型的DDD开发模式,轻Service重Domain。
基于充血模型的DDD设计模式的概念,今天只是简单地介绍了一下。在下面,会结合具体的项目,通过代码来给你展示,如何基于这种开发模式来开发一个系统。
为什么基于贫血模型的传统开发模式如此受欢迎?
前面我们讲过,基于贫血模型的传统开发模式,将数据与业务逻辑分离,违反了OOP的封装特性,实际上是一种面向过程的编程风格。但是,现在几乎所有的Web项目,都是基于这种贫血模型的开发模式,甚至连Java Spring框架的官方demo,都是按照这种开发模式来编写的。
我们前面也讲过,面向过程编程风格有种种弊端,比如,数据和操作分离之后,数据本身的操作就不受限制了。任何代码都可以随意修改数据。既然基于贫血模型的这种传统开发模式是面向过程编程风格的,那它又为什么会被广大程序员所接受呢?关于这个问题,总结了下面三点原因。
第一点原因是,大部分情况下,我们开发的系统业务可能都比较简单,简单到就是基于SQL的CRUD操作,所以,我们根本不需要动脑子精心设计充血模型,贫血模型就足以应付这种简单业务的开发工作。除此之外,因为业务比较简单,即便我们使用充血模型,那模型本身包含的业务逻辑也并不会很多,设计出来的领域模型也会比较单薄,跟贫血模型差不多,没有太大意义。
第二个原因是,充血模型的设计要比贫血模型更加有难度。因为充血模型是一种面向对象的编程风格。我们从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。而不是像贫血模型那样,我们只需要定义数据,之后有什么功能开发需求,我们就在Service层定义什么操作,不需要事先做太多设计。
第三点原因是,思维已固化,转型有成本。基于贫血模型的传统开发模式经历了这么多年,已经深得人心、习以为常。你随便问一个旁边的大龄同事,基本上他过往参与的所有Web项目应该都是基于这个开发模式的,而且也没有出过啥大问题。如果转向用充血模型、领域驱动设计,那势必有一定的学习成本、转型成本。很多人在没有遇到开发痛点的情况下,是不愿意做这件事情的。
什么项目应该考虑使用基于充血模型的DDD开发模式?
既然基于贫血模型的的开发模式已经称为了一种约定俗成的开发习惯,那什么样的项目应该考虑使用基于充血模型的DDD开发模式呢?
刚刚我们讲到,基于贫血模型的传统的开发模式,比较适合业务比较简单的系统开发。相对应的,基于充血模型的DDD开发模式,更适合业务复杂的系统开发。比如,包含各种利息计算模型、还款模型等复杂业务的金融系统。
你可能会有一些疑问,这两种开发模式,落实到代码层面,区别不就是一个将业务逻辑放到Service类中,一个将业务逻辑放到Domain领域模型中吗?为什么基于贫血模型的传统开发模式,就不能应对复杂业务系统的开发?而基于充血模型的DDD开发模式就可以呢?
实际上,除了我们能看到的代码层面的区别之外(一个业务逻辑放到Service层,一个放到领域模型中),还有一个非常重要的区别,那就是两种不同的开发模式会导致不同的开发流程。基于充血模型的DDD开发模式的开发流程,在应对复杂业务系统的开发的时候更加有优势。为什么这么说呢?我们先来回忆一下,我们平时基于贫血模型的传统的开发模式,都是怎么实现一个功能需求的。
不夸张地说,我们平时的开发,大部分都是SQL驱动(SQL-Driven)的开发模式。我们接到一个后端接口的开发需求的时候,就去看接口需要的数据对应到数据库中,需要哪张表或者哪几张表,然后思考如何编写SQL语句来获取数据。之后就是定义Entity、BO、VO,然后模板式的往对应的Repository、Service、Controller类中添加代码。
业务逻辑包裹在一个大的SQL语句中,而Service层可以做的事情很少。SQL都是针对特定的业务功能编写的,复用性差。当我要开发另一个业务功能的时候,只能重新写个满足新需求的SQL语句,这就可能导致各种长得差不多、区别很小的SQL语句满天飞。
所以,在这个过程中,很少有人会应用领域模型、OOP的概念,也很少有代码复用意识。对于简单业务系统来说,这种开发方式问题不大。但对于复杂业务系统的开发来说,这样的开发方式会让代码越来越混乱,最终导致无法维护。
如果我们在项目中,应用基于充血模型的DDD的开发模式,那对应的开发流程就完全不一样了。在这种开发模式下,我们需要实现理清所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成。
我们知道,越复杂的系统,对代码的复用性、易维护性要求就越高,我们就越应该花更多的时间和精力在前期设计上。而基于充血模型的DDD开发模式,正好需要我们前期做大量的业务调研、领域模型设计,所以它更加适合这种复杂系统的开发。
重点回顾
我们平时做Web项目的业务开发,大部分都是基于贫血模型的MVC三层架构,我把它称为传统的开发模式。之所以称之为"传统",是相对于新兴的基于充血模型的DDD开发模式来说的。基于贫血模型的传统开发模式,是典型的面向过程的变成风格。相反,基于充血模型的DDD开发模式,是典型的面向对象的变成分各个。
不过,DDD也并非银弹。对于业务不复杂的系统开发来说,基于贫血模型的传统开发模式简单够用,基于充血模型的DDD开发模式有点大材小用,无法发挥作用。相反,对于业务复杂的系统开发来说,基于充血模型的DDD开发模式,因为前期需要在设计上投入更多时间和精力,来提高代码的复用性和可维护性,所以相比基于贫血模型的开发模式,更加有优势。
先说一下充血模型中各组件的角色:
* controller 主要服务于非业务功能,比如说数据验证 * service 服务于 use case,负责的是业务流程与对应规则 * Domain 服务于核心业务逻辑和核心业务数据 * rep 用于与外部交互数据
六边形项目结构(根据实际情况自行组织与定义):
* InboundHandler 代替 controller * WebController:处理 web 接口 * WeChatController:处理微信公众号接口 * AppController:处理 app 接口 * MqListener:处理 消息 * *RpcController:处理子系统间的调用 * service 服务于 use case,负责的是业务流程与对应规则 * CQPS + SRP:读写分离和单一原则将 use case 分散到不同的 service 中,避免一个巨大的 service 类(碰到过 8000 行的 service) * Domain 服务于核心业务逻辑和核心业务数据 * 最高层组件,不会依赖底层组件 * 易测试 * outBoundhandle 代替 rep * MqProducer:发布消息 * Cache:从缓存获取数据 * sql:从数据库获取数据 * Rpc:从子系统获取数据
各层之间的数据模型不要共用,主要是因为稳定性不同,各层数据模型的变更原因和变更速率是不同的,离 IO 设备越近的稳定性越差,比如说 controller 层的 VO,rep 层的 entity。Domain 层是核心业务逻辑和核心业务数据,稳定性是最高的