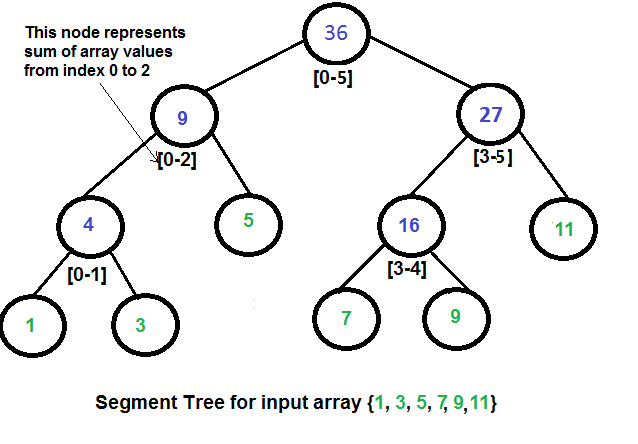
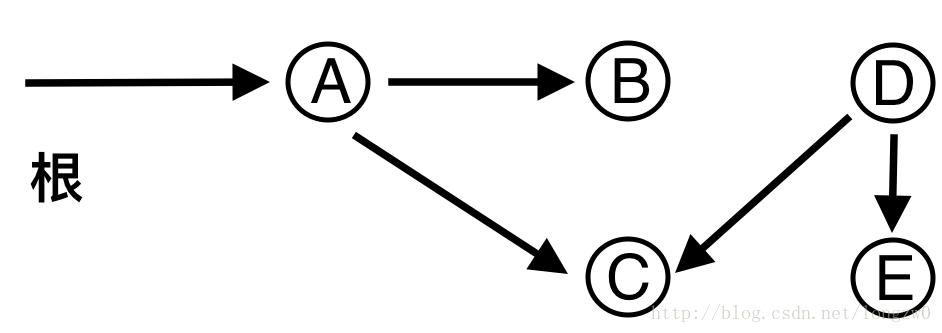
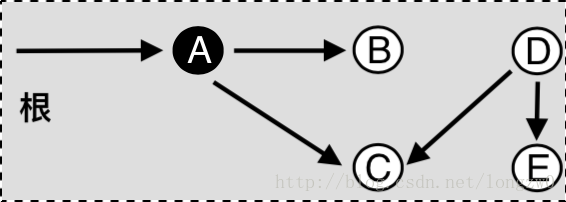
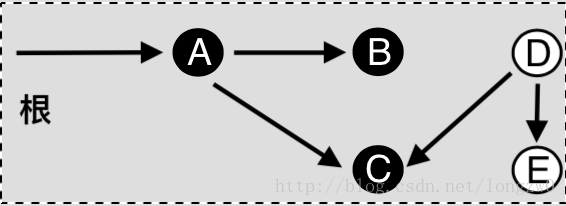
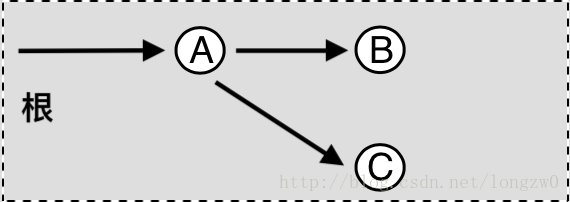
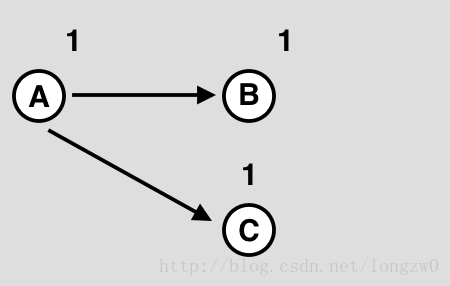
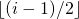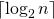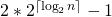We have an array arr[0 . . . n-1]. We would like to 1 Compute the sum of the first i elements. 2 Modify the value of a specified element of the array arr[i] = x where 0 <= i <= n-1.
A simple solution is to run a loop from 0 to i-1 and calculate the sum of the elements. To update a value, simply do arr[i] = x. The first operation takes O(n) time and the second operation takes O(1) time.
Another simple solution is to create an extra array and store the sum of the first i-th elements at the i-th index in this new array. The sum of a given range can now be calculated in O(1) time, but the update operation takes O(n) time now. This works well if there are a large number of query operations but a very few number of update operations.
Could we perform both the query and update operations in O(log n) time? One efficient solution is to use Segment Tree that performs both operations in O(Logn) time.
An alternative solution is Binary Indexed Tree, which also achieves O(Logn) time complexity for both operations. Compared with Segment Tree, Binary Indexed Tree requires less space and is easier to implement..
Representation Binary Indexed Tree is represented as an array. Let the array be BITree[]. Each node of the Binary Indexed Tree stores the sum of some elements of the input array. The size of the Binary Indexed Tree is equal to the size of the input array, denoted as n. In the code below, we use a size of n+1 for ease of implementation.
Construction We initialize all the values in BITree[] as 0. Then we call update() for all the indexes, the update() operation is discussed below.
Operations
1 2 3 4 5 6 7 8
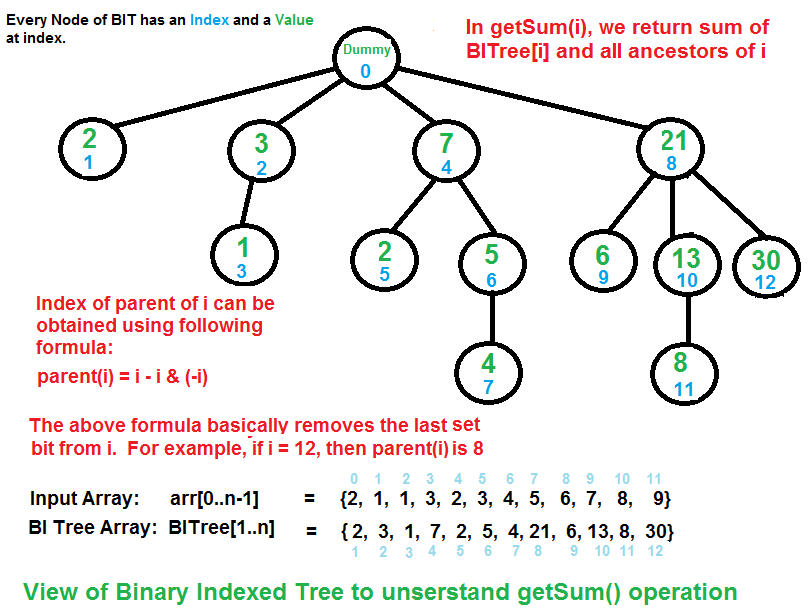
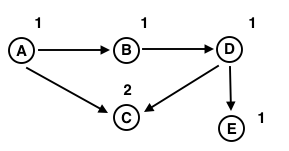
getSum(x): Returns the sum of the sub-array arr[0,...,x] // Returns the sum of the sub-array arr[0,...,x] using BITree[0..n], which is constructed from arr[0..n-1] 1) Initialize the output sum as 0, the current index as x+1. 2) Do following while the current index is greater than 0. ...a) Add BITree[index] to sum ...b) Go to the parent of BITree[index]. The parent can be obtained by removing the last set bit from the current index, i.e., index = index - (index & (-index))【index&(index-1) 也可以】 3) Return sum.
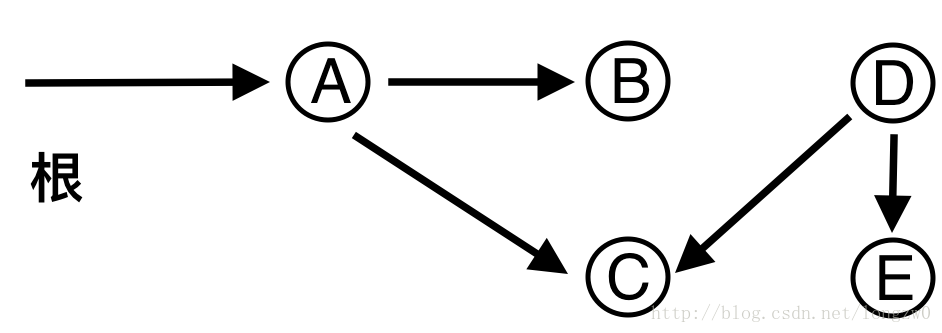
The diagram above provides an example of how getSum() is working. Here are some important observations.
BITree[0] is a dummy node.
BITree[y] is the parent of BITree[x], if and only if y can be obtained by removing the last set bit from the binary representation of x, that is y = x – (x & (-x)).【index&(index-1) 也可以】
The child node BITree[x] of the node BITree[y] stores the sum of the elements between y(inclusive) and x(exclusive): arr[y,…,x).
1 2 3 4 5 6 7
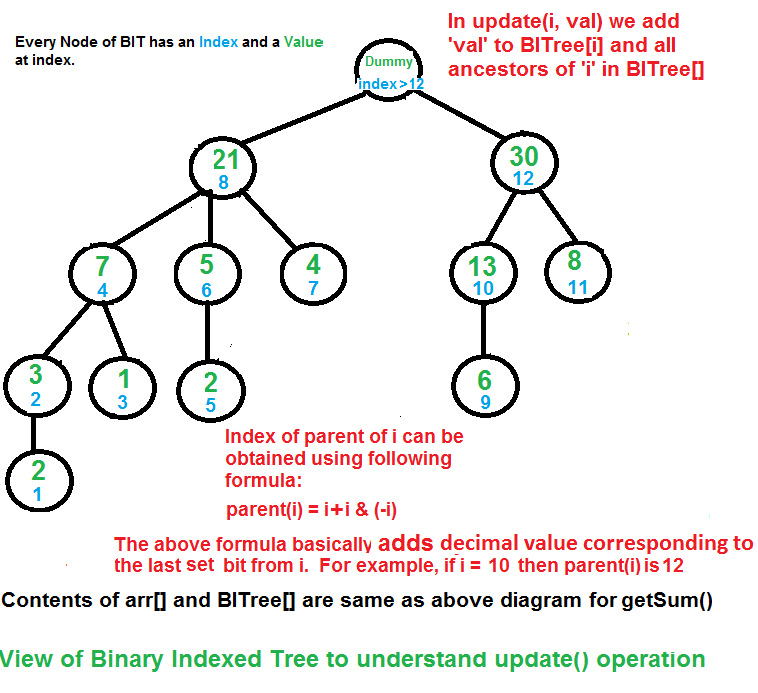
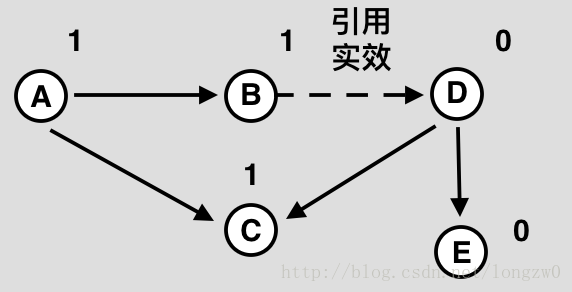
update(x, val): Updates the Binary Indexed Tree (BIT) by performing arr[index] += val // Note that the update(x, val) operation will not change arr[]. It only makes changes to BITree[] 1) Initialize the current index as x+1. 2) Do the following while the current index is smaller than or equal to n. ...a) Add the val to BITree[index] ...b) Go to parent of BITree[index]. The parent can be obtained by incrementing the last set bit of the current index, i.e., index = index + (index & (-index))
The update function needs to make sure that all the BITree nodes which contain arr[i] within their ranges being updated. We loop over such nodes in the BITree by repeatedly adding the decimal number corresponding to the last set bit of the current index.
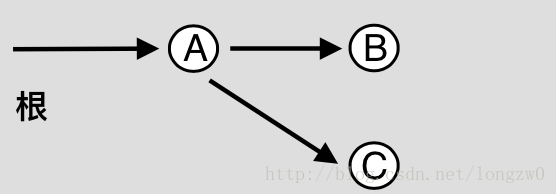
How does Binary Indexed Tree work? The idea is based on the fact that all positive integers can be represented as the sum of powers of 2. For example 19 can be represented as 16 + 2 + 1. Every node of the BITree stores the sum of n elements where n is a power of 2. For example, in the first diagram above (the diagram for getSum()), the sum of the first 12 elements can be obtained by the sum of the last 4 elements (from 9 to 12) plus the sum of 8 elements (from 1 to 8). The number of set bits in the binary representation of a number n is O(Logn). Therefore, we traverse at-most O(Logn) nodes in both getSum() and update() operations. The time complexity of the construction is O(nLogn) as it calls update() for all n elements.
Consider a situation where we have a set of intervals and we need following operations to be implemented efficiently. 1) Add an interval 2) Remove an interval 3) Given an interval x, find if x overlaps with any of the existing intervals.
考虑我们有一个集合的区间,并且我们需要以下操作能够有效率的实现:
添加一个区间
删除一个区间
对于一个给定的区间x,找出x是否有和任意一个已经存在的区间有重合。
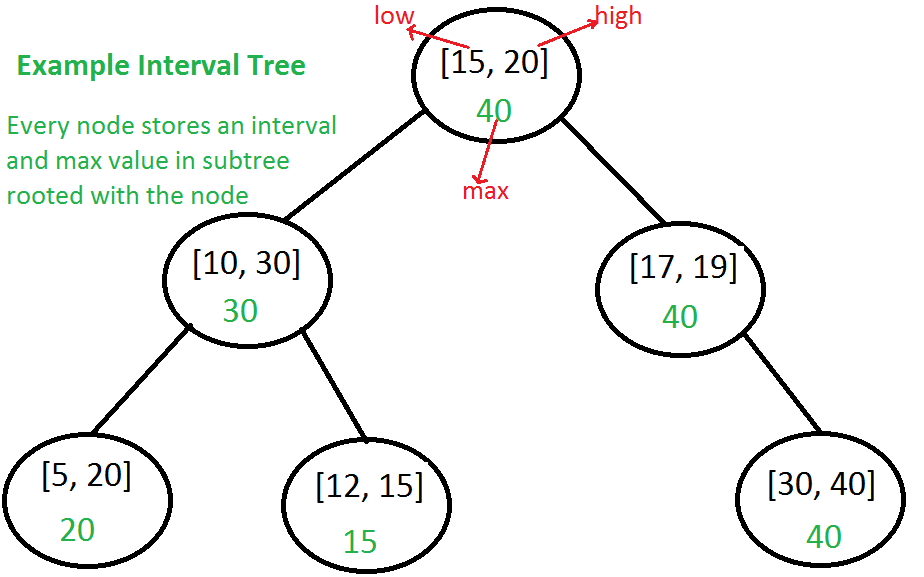
Interval Tree: The idea is to augment a self-balancing Binary Search Tree (BST) like Red Black Tree, AVL Tree, etc to maintain set of intervals so that all operations can be done in O(Logn) time.
Every node of Interval Tree stores following information. a) i: An interval which is represented as a pair [low, high] b) max: Maximum high value in subtree rooted with this node.
区间的最小值用作BST的键值来保持BST的顺序。那么插入和删除就和自平衡BST的插入删除一样。
那么我们就来看找重合区间的操作。
Following is algorithm for searching an overlapping interval x in an Interval tree rooted with root.
1 2 3 4 5 6 7
Interval overlappingIntervalSearch(root, x) 1) If x overlaps with root's interval, return the root's interval.
2) If left child of root is not empty and the max in left child is greater than x's low value, recur for left child
3) Else recur for right child.
How does the above algorithm work? Let the interval to be searched be x. We need to prove this in for following two cases.
Case 1:When we go to right subtree, one of the following must be true. a) There is an overlap in right subtree: This is fine as we need to return one overlapping interval. b) There is no overlap in either subtree: We go to right subtree only when either left is NULL or maximum value in left is smaller than x.low. So the interval cannot be present in left subtree.
Case 2:When we go to left subtree, one of the following must be true. a) There is an overlap in left subtree: This is fine as we need to return one overlapping interval. b) There is no overlap in either subtree: This is the most important part. We need to consider following facts. … We went to left subtree because x.low <= max in left subtree …. max in left subtree is a high of one of the intervals let us say [a, max] in left subtree. …. Since x doesn’t overlap with any node in left subtree x.low must be smaller than ‘a‘. …. All nodes in BST are ordered by low value, so all nodes in right subtree must have low value greater than ‘a‘. …. From above two facts, we can say all intervals in right subtree have low value greater than x.low. So x cannot overlap with any interval in right subtree.
Applications of Interval Tree: Interval tree is mainly a geometric data structure and often used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene (Source Wiki).
Interval Tree vs Segment Tree Both segment and interval trees store intervals. Segment tree is mainly optimized for queries for a given point, and interval trees are mainly optimized for overlapping queries for a given interval.
Let us consider the following problem to understand Segment Trees.
We have an array arr[0 . . . n-1]. We should be able to 1 Find the sum of elements from index l to r where 0 <= l <= r <= n-1
2 Change value of a specified element of the array to a new value x. We need to do arr[i] = x where 0 <= i <= n-1.
A simple solution is to run a loop from l to r and calculate the sum of elements in the given range. To update a value, simply do arr[i] = x. The first operation takes O(n) time and the second operation takes O(1) time.
Another solution is to create another array and store sum from start to i at the ith index in this array. The sum of a given range can now be calculated in O(1) time, but update operation takes O(n) time now. This works well if the number of query operations is large and very few updates.
What if the number of query and updates are equal? Can we perform both the operations in O(log n) time once given the array? We can use a Segment Tree to do both operations in O(Logn) time.
Representation of Segment trees1. Leaf Nodes are the elements of the input array. 2. Each internal node represents some merging of the leaf nodes. The merging may be different for different problems. For this problem, merging is sum of leaves under a node.
An array representation of tree is used to represent Segment Trees. For each node at index i, the left child is at index 2i+1, right child at 2i+2 and the parent is at .
How does above segment tree look in memory? Like Heap, the segment tree is also represented as an array. The difference here is, it is not a complete binary tree. It is rather a full binary tree (every node has 0 or 2 children) and all levels are filled except possibly the last level. Unlike Heap, the last level may have gaps between nodes. Below are the values in the segment tree array for the above diagram.
Below is memory representation of segment tree for input array {1, 3, 5, 7, 9, 11}st[] = {36, 9, 27, 4, 5, 16, 11, 1, 3, DUMMY, DUMMY, 7, 9, DUMMY, DUMMY}
The dummy values are never accessed and have no use. This is some wastage of space due to simple array representation. We may optimize this wastage using some clever implementations, but code for sum and update becomes more complex.
Construction of Segment Tree from given array We start with a segment arr[0 . . . n-1]. and every time we divide the current segment into two halves(if it has not yet become a segment of length 1), and then call the same procedure on both halves, and for each such segment, we store the sum in the corresponding node. All levels of the constructed segment tree will be completely filled except the last level. Also, the tree will be a Full Binary Tree because we always divide segments in two halves at every level. Since the constructed tree is always a full binary tree with n leaves, there will be n-1 internal nodes. So the total number of nodes will be 2*n – 1. Note that this does not include dummy nodes.
What is the total size of the array representing segment tree? If n is a power of 2, then there are no dummy nodes. So the size of the segment tree is 2n-1 (n leaf nodes and n-1) internal nodes. If n is not a power of 2, then the size of the tree will be 2*x – 1 where x is the smallest power of 2 greater than n. For example, when n = 10, then size of array representing segment tree is 2*16-1 = 31. An alternate explanation for size is based on heignt. Height of the segment tree will be . Since the tree is represented using array and relation between parent and child indexes must be maintained, size of memory allocated for segment tree will be .
Query for Sum of given range Once the tree is constructed, how to get the sum using the constructed segment tree. The following is the algorithm to get the sum of elements.
1 2 3 4 5 6 7 8 9 10
intgetSum(node, l, r) { if the range of the node is within l and r return value in the node elseif the range of the node is completely outside l and r return0 else return getSum(node's left child, l, r) + getSum(node's right child, l, r) }
Update a value Like tree construction and query operations, the update can also be done recursively. We are given an index which needs to be updated. Let diff be the value to be added. We start from the root of the segment tree and add diff to all nodes which have given index in their range. If a node doesn’t have a given index in its range, we don’t make any changes to that node.
Implementation: Following is the implementation of segment tree. The program implements construction of segment tree for any given array. It also implements query and update operations.
# Python3 program to show segment tree operations like # construction, query and update from math import ceil, log2;
# A utility function to get the # middle index from corner indexes. defgetMid(s, e) : return s + (e -s) // 2;
""" A recursive function to get the sum of values in the given range of the array. The following are parameters for this function. st --> Pointer to segment tree si --> Index of current node in the segment tree. Initially 0 is passed as root is always at index 0 ss & se --> Starting and ending indexes of the segment represented by current node, i.e., st[si] qs & qe --> Starting and ending indexes of query range """ defgetSumUtil(st, ss, se, qs, qe, si) :
# If segment of this node is a part of given range, # then return the sum of the segment if (qs <= ss and qe >= se) : return st[si];
# If segment of this node is # outside the given range if (se < qs or ss > qe) : return0;
# If a part of this segment overlaps # with the given range mid = getMid(ss, se); return getSumUtil(st, ss, mid, qs, qe, 2 * si + 1) + \ getSumUtil(st, mid + 1, se, qs, qe, 2 * si + 2);
""" A recursive function to update the nodes which have the given index in their range. The following are parameters st, si, ss and se are same as getSumUtil() i --> index of the element to be updated. This index is in the input array. diff --> Value to be added to all nodes which have i in range """ defupdateValueUtil(st, ss, se, i, diff, si) :
# Base Case: If the input index lies # outside the range of this segment if (i < ss or i > se) : return;
# If the input index is in range of this node, # then update the value of the node and its children st[si] = st[si] + diff; if (se != ss) : mid = getMid(ss, se); updateValueUtil(st, ss, mid, i, diff, 2 * si + 1); updateValueUtil(st, mid + 1, se, i, diff, 2 * si + 2);
# The function to update a value in input array # and segment tree. It uses updateValueUtil() # to update the value in segment tree defupdateValue(arr, st, n, i, new_val) :
# Check for erroneous input index if (i < 0or i > n - 1) : print("Invalid Input", end = ""); return;
# Get the difference between # new value and old value diff = new_val - arr[i];
# Update the value in array arr[i] = new_val;
# Update the values of nodes in segment tree updateValueUtil(st, 0, n - 1, i, diff, 0);
# Return sum of elements in range from # index qs (quey start) to qe (query end). # It mainly uses getSumUtil() defgetSum(st, n, qs, qe) :
# Check for erroneous input values if (qs < 0or qe > n - 1or qs > qe) :
print("Invalid Input", end = ""); return-1; return getSumUtil(st, 0, n - 1, qs, qe, 0);
# A recursive function that constructs # Segment Tree for array[ss..se]. # si is index of current node in segment tree st defconstructSTUtil(arr, ss, se, st, si) :
# If there is one element in array, # store it in current node of # segment tree and return if (ss == se) : st[si] = arr[ss]; return arr[ss]; # If there are more than one elements, # then recur for left and right subtrees # and store the sum of values in this node mid = getMid(ss, se); st[si] = constructSTUtil(arr, ss, mid, st, si * 2 + 1) +\ constructSTUtil(arr, mid + 1, se, st, si * 2 + 2); return st[si];
""" Function to construct segment tree from given array. This function allocates memory for segment tree and calls constructSTUtil() to fill the allocated memory """ defconstructST(arr, n) :
# Allocate memory for the segment tree
# Height of segment tree x = (int)(ceil(log2(n)));
# Maximum size of segment tree max_size = 2 * (int)(2**x) - 1; # Allocate memory st = [0] * max_size;
# Fill the allocated memory st constructSTUtil(arr, 0, n - 1, st, 0);
# Return the constructed segment tree return st;
# Driver Code if __name__ == "__main__" :
arr = [1, 3, 5, 7, 9, 11]; n = len(arr);
# Build segment tree from given array st = constructST(arr, n);
# Print sum of values in array from index 1 to 3 print("Sum of values in given range = ", getSum(st, n, 1, 3));
# Update: set arr[1] = 10 and update # corresponding segment tree nodes updateValue(arr, st, n, 1, 10);
# Find sum after the value is updated print("Updated sum of values in given range = ", getSum(st, n, 1, 3), end = "");
Output:
1 2
Sum of values in given range = 15 Updated sum of values in given range = 22
Time Complexity: Time Complexity for tree construction is O(n). There are total 2n-1 nodes, and value of every node is calculated only once in tree construction.
Time complexity to query is O(Logn). To query a sum, we process at most four nodes at every level and number of levels is O(Logn).
The time complexity of update is also O(Logn). To update a leaf value, we process one node at every level and number of levels is O(Logn).
示例题目
SPOJ-GSS1
You are given a sequence A[1], A[2], ..., A[N] . ( |A[i]| ≤ 15007 , 1 ≤ N ≤ 50000 ). A query is defined as follows: Query(x,y) = Max { a[i]+a[i+1]+...+a[j] ; x ≤ i ≤ j ≤ y }. Given M queries, your program must output the results of these queries.
Input
The first line of the input file contains the integer N.
In the second line, N numbers follow.
The third line contains the integer M.
M lines follow, where line i contains 2 numbers xi and yi.
Output
Your program should output the results of the M queries, one query per line.
Example
1 2 3 4 5 6 7 8
Input: 3 -1 2 3 1 1 2
Output: 2
大致翻译:给定一段长度为n的序列a1, a2, ..., an (a有正有负),每次询问[L, R] (即aL ~ aR)范围内的最大子段和,并涉及单点修改操作。
线段树:维护区间最大子段和。
这里不能用传统的线段树了,我们维护的值要更多。
定义:
线段树一共要维护4个值,如下:(每个值的含义都是相对于该结点对应区间[l, r]而言)
1 2 3 4 5 6 7 8
structnode { int sum; //[l,r]区间之和 int max_sum; //[l,r]内的最大子段和 int max_pre; //[l,r]内的最大前缀和 int max_post; //[l,r]内的最大后缀和 }t[maxn<<2];
# f(i) s[:i]的最大子序和,且一定包括i # f(i) = max(f(i-1), 0) + a[i] classSolution: defmaxSubArray(self, nums: List[int]) -> int: pre, cur = float('-inf'), float('-inf') for n in nums: pre = max(pre + n, n) cur = max(cur, pre) return cur
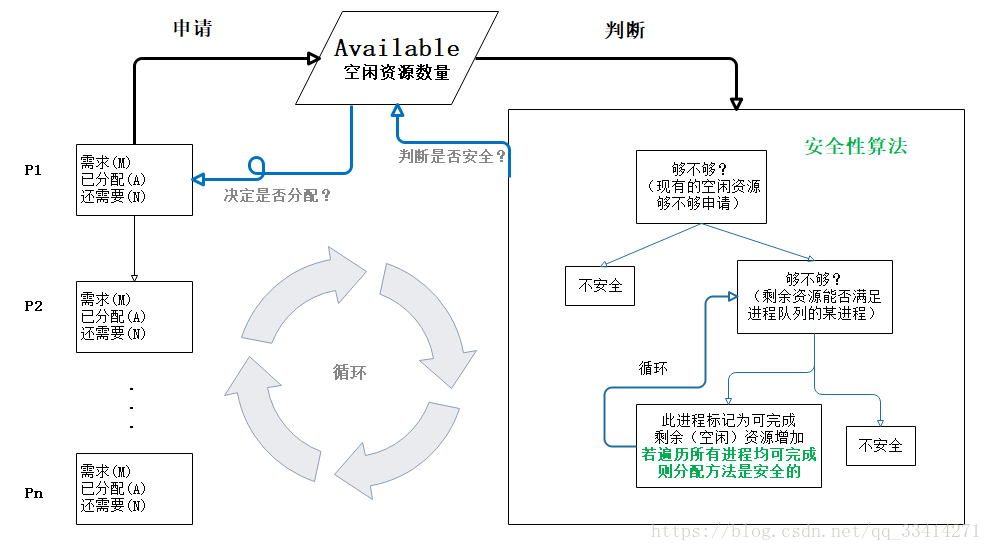
while (P != ∅) { found = FALSE; foreach (p ∈ P) { // Mp - Cp就是Need if (Mp − Cp ≤ A) { /* p可以获得他所需的资源。假设他得到资源后执行;执行终止,并释放所拥有的资源。*/ A = A + Cp ; P = P − {p}; found = TRUE; } } if (! found) return FAIL; } return OK;
你知道存在楼层 F ,满足 0 <= F <= N 任何从高于 F 的楼层落下的鸡蛋都会碎,从 F 楼层或比它低的楼层落下的鸡蛋都不会破。
每次移动,你可以取一个鸡蛋(如果你有完整的鸡蛋)并把它从任一楼层 X 扔下(满足 1 <= X <= N)。
你的目标是确切地知道 F 的值是多少。
无论 F 的初始值如何,你确定 F 的值的最小移动次数是多少?
示例 1:
输入:K = 1, N = 2 输出:2 解释: 鸡蛋从 1 楼掉落。如果它碎了,我们肯定知道 F = 0 。 否则,鸡蛋从 2 楼掉落。如果它碎了,我们肯定知道 F = 1 。 如果它没碎,那么我们肯定知道 F = 2 。 因此,在最坏的情况下我们需要移动 2 次以确定 F 是多少。 示例 2:
输入:K = 2, N = 6 输出:3 示例 3:
输入:K = 3, N = 14 输出:4
提示:
1 <= K <= 100 1 <= N <= 10000
思路
基本想法
首先,我们可以看到要得到较大的楼层和鸡蛋的答案,小的情况下的结果是有用的分析,这就导致了动态递推。
定义子问题,也就是定义子状态。
我们有两个变量
还有多少可以扔的鸡蛋 i ,(0 <= i <= K)
还剩下几层楼来测试 j ,(i <= j <= N)
结果就是我们子问题
dp[i][j]就是在还有i个鸡蛋,j层楼的时候,我们要得到这个目标楼层所用的最小次数。
DP方程
初始化
1 2 3
dp[1][j] = j, j = 1...N # one egg, check each floor from 1 to j dp[i][0] = 0, i = 1...K # no floor, no drop needed to get the optimal floor dp[i][1] = 1, i = 1...K # one floor, only check once
classSolution: defsuperEggDrop(self, K: int, N: int) -> int: dp = [[float('inf')] * (N + 1) for _ in range(K + 1)] for i in range(1, K + 1): dp[i][0] = 0 dp[i][1] = 1 for j in range(1, N + 1): dp[1][j] = j
for i in range(2, K + 1): for j in range(2, N + 1): for k in range(1, j + 1): dp[i][j] = min(dp[i][j], 1 + max(dp[i - 1][k - 1], dp[i][j - k])) return dp[K][N]
或者减少空间复杂度的下面代码
1 2 3 4 5 6 7 8 9 10
classSolution: defsuperEggDrop(self, K: int, N: int) -> int: dp = list(range(N + 1)) _dp = [0] * (N + 1) for _ in range(K - 1): for j in range(1, N + 1): _dp[j] = 1 + min(max(dp[k - 1], _dp[j - k]) for k in range(1, j + 1)) dp, _dp = _dp, dp return dp[N]
classSolution: defsuperEggDrop(self, K: int, N: int) -> int: dp = [[float('inf')] * (N + 1) for _ in range(K + 1)] for i in range(1, K + 1): dp[i][0] = 0 dp[i][1] = 1 for j in range(1, N + 1): dp[1][j] = j
for i in range(2, K + 1): k = 1 for j in range(2, N + 1): while k < j + 1and dp[i][j - k] > dp[i - 1][k - 1]: k += 1 dp[i][j] = 1 + dp[i - 1][k - 1] return dp[K][N]