首先官方文档是这么写的。参考MySQL5.6 Ref manual。
每个InnoDB表都有一个特殊的索引,称为聚簇索引clustered index,行的数据就存储在这里。通常情况下,聚簇索引是主键的同义词。为了从查询、插入和其他数据库操作中获得最佳性能,你必须理解InnoDB是如何使用聚簇索引来优化每个表的最常见的查找和DML操作的。
- 当你在表上定义一个primary key时,InnoDB就会把它作为聚簇索引。为你创建的每一个表定义一个主键。如果没有逻辑上唯一且非空的列或列集合,则添加一个新的自动增加列,其值会自动填入。
- 如果你没有为你的表定义primary key,MySQL会定位第一个Unique索引,其中所有的关键列都是Not Null。InnoDB使用它作为聚簇索引。
- 如果表没有primary key或合适的unique索引,InnoDB内部会在包含row id值的合成列上生成一个名为GEN_CLUST_INDEX的隐藏聚簇索引。行是由InnoDB分配给这种表中的行的ID来排序的。row id是一个6字节的字段,随着新行的插入而单调增加。因此,按row id排序的行在物理上是按插入顺序排列的。
聚簇索引是如何加快查询速度的?
通过聚簇索引访问行的速度很快,因为索引搜索会直接引导到包含所有行数据的页面。如果一张表很大,与使用与索引记录不同的页面存储行数据的存储组织相比,聚簇索引架构往往可以节省一次磁盘I/O操作。
二级索引与聚簇索引的关系
除了聚簇索引以外的所有索引都称为二级索引。在InnoDB中,二级索引中的每条记录都包含改行的主键列,以及二级索引指定的列。InnoDB使用这个主键值来搜索聚簇索引中的行。
如果主键长,二级索引就会使用更多的空间,所以主键短是有利的。
回答标题的问题
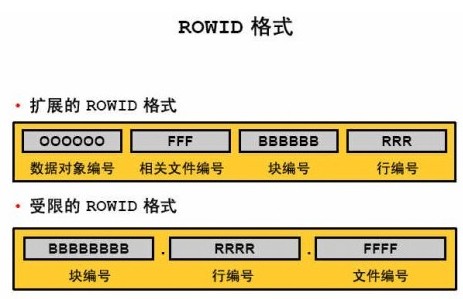
这里我没有找到mysql的rowid为什么是6个字节的答案,找到是关于oracle rowid的解释,猜测是互通的。
rowid是伪列。不会真正存在表的data block中,但是它会存在于index中。
扩展的rowid在磁盘上需要10个字节的存储空间,并使用18个字符来显示。
解释如下:
在oracle 8以前,一个rowid占用6个字节大小的存储空间(10 bit file# + 22bit block # + 16 bit row #),rowid格式为:BBBBBBBB.RRRR.FFFF。
在oracle 8以后,rowid的存储空间扩大到了10个字节(32 bit object# + 10bit rfile# + 22 bit block# + 16 bit row#),文件号仍然用10位表示,只是不再需要置换,为了向后兼容,同时引入了相对文件号(rfile#),所以从Oracle7到Oracle8,rowid仍然无需发生变化。
这里我猜测,mysql rowid也是存储了 10位的文件号,22位的块号,16位的行号。
更新:已经得到答案。
详见文章