epoll 网络事件收集器模型(也有分发)
nginx事件分发机制,在其中的循环流程中,最关键的就是,nginx怎样能够快速的从操作系统的kernal中获取到等待处理的事件,这么一个简单的步骤,其实,经历了很长时间的解决。比如,到现在nginx主要在使用epoll这样一个网络事件收集器的模型。那么,下面我们来简单的回顾下,epoll有些什么样的特点。
首先,epoll 和 kqueue(mac os内核才有)随文件描述符(句柄数的增加,也表示并发连接数的增加)的增加,所消耗的时间几乎不变。而Poll和select所消耗的时间是急剧上升的。epoll基本与句柄数增加是无关的,所以它的性能会好很多,而且非常适合做大并发连接的处理。那么,为什么会这样呢?
Benchmark显示:
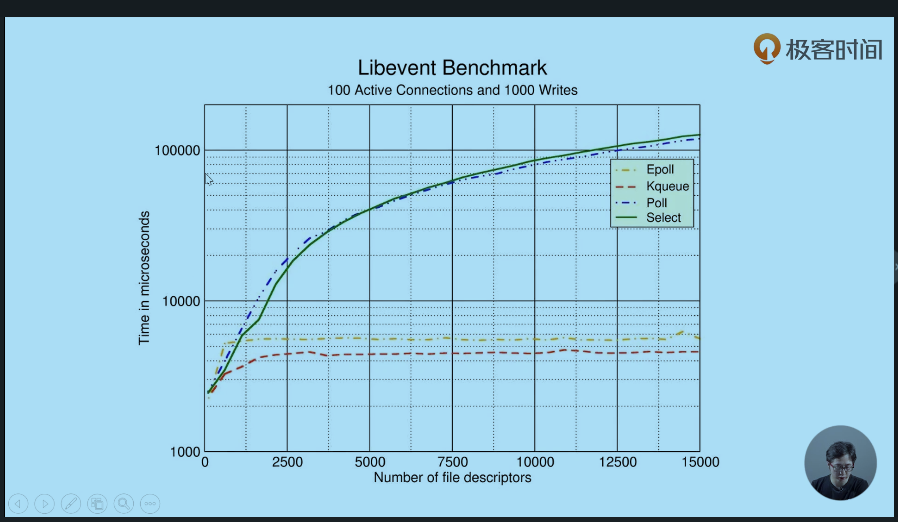
前提
高并发连接中,每次处理的活跃连接数量占比很小
select 和 poll的实现是有问题的。每一次我去取操作系统的事件的时候,我都需要把这100万个连接通通地扔给操作系统,让它去依次地判断哪些连接上面有事件进来了,所以可以看到这里操作系统做了大量的无用功 ,它扫描了大量不活跃的连接。那么epoll就是用了这样的一个特性,因为每次处理的活跃连接的占比其实非常小,那么,它怎么实现的呢?其实非常简单,因为它维护了一个数据结构叫eventpoll。这里,它通过两个数据结构把这两件事分开了。也就是说,nginx每次取活跃连接的时候,我们只需要去遍历一个链表,这个链表里仅仅只有活跃的连接,这样我们的效率就很高。那么,我们还会经常做的操作是什么呢?比如说,nginx收到80端口建立连接的请求。那么,收到80端口建立连接成功以后呢,我们要添加一个读事件,这个读事件是用来读取HTTP消息的,那这时候呢,我可能会添加一个新的事件,或者写事件添加进来。这个时候添加呢,我只会放到这个红黑树中,这个二叉平衡树,它能保证我的插入效率值是logn。如果我现在不想再处理读事件或者写事件,我只需要从这个平衡二叉树中移除一个节点就可以了,同样是logn的时间复杂度。所以这个效率非常高。那么什么时候这个链表会有所增减呢。当我们读取一个事件的时候,链表中自然就没了。那么,当操作系统接收到网卡中发送来的一个报文的时候,那么这个链表就会增加一个新的元素,所以我们在使用epoll的时候,它的操作,添加修改删除,是非常快的,是logn复杂度的。而我们获取句柄的时候,只是去遍历这个rdllink,也就是ready准备好的所有的连接,是把它读取出来而已。那么,从内核态读取到用户态,只读这么一点东西,它的效率是非常高的。
实现
- 红黑树
- 链表
使用
- 创建
- 操作:添加/修改/删除
- 获取句柄
- 关闭
以上,简单介绍了epoll的使用方法,它对我们理解nginx的事件驱动模型是有帮助的。
其他
每一个nginx worker进程都有一个独立的ngx_cycle_t这样一个数据结构。有三个主要的数组,connections,read_events,write_events。分别代表预分配的连接、读事件和写事件。三个数组大小和配置是一模一样的,三个数组通过序号对应起来。
每一个connection到底使用了多大的内存呢?连接使用的核心数据结构是ngx_connection_s,64位操作系统中,大约占用了232个字节,nginx版本不同可能有微小的差异,每一个ngx_connetion_s结构体对应着两个事件,一个读一个写,每一个时间对应的结构体,事件的核心数据结构是ngx_event_s,结构体占用的字节数是96字节。所以当我们使用一个连接的时候,它使用的字节大约是232+96*2,我们的worker connections配置得越大,那么初始化的时候就会预分配这么多内存。
我们再来看ngx_event_s中有哪些成员,这里我们比较关注的是,有一个handler(ngx_event_gandler_pt)指针,这是一个回调方法,也就是很多第三方模块会把这个handler设为自己的实现;这里还有一个timer(ngx_rbtree_node_t),也就是说,当我们对http请求做读超时写超时等等设置的时候,其实是在操作它的读事件和写事件中的timer,这个timer就是inginx实现超时定时器,也就是基于rbtree就实现的这样一个结构体。那么红黑树中每个成员叫rbtree_node,那么这个timer就是它的node,用来指向我们的读事件是否超时、写事件是否超时,这些定时器其实也是可配的。
比如client_header_timeout,默认是60s,也就是在我们刚刚某个连接上,在准备读取它的header时,我们在它的读事件上添加了一个60s的定时器。
当多个事件形成队列的时候,可以用这个ngx_queue_t形成一个队列。
我们再来简单的看一下,ngx_connection_s有一些什么样的成员。ngx_event_t read,ngx_event_t write分别是它的读写事件,这个刚刚已经说过了。recv和send是它抽象的操作系统的底层方法,怎么样发送和接收。这里还有一个比较有意思的变量,叫做sent,它的类型是off_t,大家可以把它理解成一个无符号的整型,表达的呢就是这个连接上我已经发送了多少字节,也就是,我们在配置中,会经常使用到的bytes_sent变量,那么我们可以先看一看bytes_sent变量到底有什么作用。还是打开ngx_http_core_module的官方文档,我们先找到它的内置变量。可以看到bytes_sent,它表示向客户端发送了多少字节。通常,在access_log记录nginx处理了哪些请求中,我们会记录这么一个变量,比如,在我们查看access_log时。现在我们打开了nginx_conf这个配置文件,在配置文件中,我们有一行log_format main,定义了access_log的日志格式。在日志格式,我们看到有一个 中括号,这个中括号的后半部分我们用了bytes_sent这个内置变量,用来表示我们发送了多少字节。我们看一下在日志中,这个bytes_sent会表现为什么样的形式。
以上谈了nginx_connection_t和nginx_event连接和事件怎么样对应在一起的,当我们配置高并发的nginx时,必须把connections的数目配置到足够大,而每一个connection相对应两个event,都会消耗一定的内存,需要我们注意。还有nginx中像很多结构体中它们的一些成员和我们内置变量是可以对应起来的,比如说bytes_sent,还有一些比如说body_bytes_sent都是我们在access_log或者说在一些openresty lua写的代码中,我们获取到nginx内置的状态时,经常使用到的方法。
如果你开发过nginx的第三方开发模块,虽然我们在写C语言代码,但是我们不需要关心内存的释放,那么如果你现在在配置一些比较罕见的nginx使用场景,你可能会需要去修改nginx在请求和连接上初始分配内存池大小。但是nginx官方可能会写着推荐通常不需要去该这样的配置。那么我们究竟要不要这些内存池的大小呢?下面,我们来看一看内存池究竟是怎么样运转的。
ngx_connection_s这样的结构体中,有一个成员变量就是pool,ngx_pool_t,它对应着这个连接所使用的的内存池。这个内存池可以通过一个配置项叫connection_pool_size去定义。那么,我们为什么会需要内存池呢,如果我们有一些工具的话我们会发现,nginx它所产生的内存碎片其实是非常小的,这就是内存池的一个功了。那么,内存池呢,它会把内存提前分配好一批,而且,当我们使用小块内存的时候 ,它会用next指针一个个连接在一起,每次我们使用的东西比较少的时候呢,第二次再分配小块内存,会连接在一起去使用,这样就大大减少了我们的内存碎片。当然我们如果分配大块内存的时候,还是会走到操作系统的alloc去分配大块的内存。那么对于nginx有什么好处呢?因为它主要在处理web请求,web请求,特别对于http请求,它有两个非常明显的特点。每当我们有一个TCP连接的时候,那么,这个TCP连接上面可能会运行很多http请求,也就是所谓的http keepalive请求,连接没有关闭,执行完一条请求以后还负责执行另外一条请求。 那么有一些内存呢,我为连接分配一次就够了,比如说,我去读取每一个请求的前1k字节,那么在连接内存池上,我分配一次,只要这个连接不关闭,那么这段1k的内存,我永远不需要释放,什么时候需要释放呢?连接关闭的时候我再释放。没有任何问题。请求内存池呢?每一个http请求,我开始分配的时候,我不知道分配多大,但是http请求,特别是http1.1而言,通常我们会分配4k的大小的内存,因为我们的url或者header往往需要分配那么多,如果没有内存池呢,我们可能需要频繁的分配,小块的分配,而分配内存,其实是有代价的,如果我们一次分配,分配较多的内存呢,就没有这样的问题。而请求执行完毕以后,哪怕连接我们还可以复用,我们也可以把请求池销毁,而这样,所有nginx第三方模块开发者,他们就不必关注,内存什么时候会释放,它只要关注,我是从请求内存池里面,申请分配的内存,还是连接内存池里,申请分配的内存。只要这个逻辑讲得通,比如请求结束以后,连接仍然想继续使用,那么你可以在连接内存池里面分配。好我们看一下具体的例子。还是在nginx_http_core_module这个模块中,我们可以看到它有一个叫connection_pool_size,点开以后可以看到默认情况下,它大约是256或者512,这个跟我们的操作系统位数是有关的。那么内存池配置512,并不代表,在这里我只能分配512字节,当我们分配的内存超过预分配的大小的时候,还是可以继续分配的,这里只是说,因为我提前预分配了足够大小的空间,可以减少我分配内存的次数。那我们再来看,另一个配置,叫request pool size也就是我们每一个请求的内存池的大小,这里我们可以看到,它的默认大小是4k,为什么差距会那么大呢?之所以会差距8倍,是因为,对于连接而言,它需要保存的上下文信息非常的少,它只需要帮助后面的请求读取最初一部分字节就可以了,而对于请求而言,我们需要保存大量的上下文信息,比如说所有读取到的url或者header,我需要一直保存下来,url通常还比较长,所以我们需要有4k的大小。当然官方文档中说,它对性能的影响比较小,如果我们在极端场景下,如果你的url特别大,你可以考虑把这个分配得更大,或者说你是很小内存的,url非常小,header也非常少,你可以考虑request_pool_size把它降一降,这样或许nginx消耗的内存会小一些,那么也意味着你可以做更大并发量的请求。
以上我们介绍了内存池的原理,以及请求内存池和连接内存池,它们的配置代表着怎样的意义。内存池对减少我们的内存碎片,对第三方模块的快速开发,是有很大意义的。可能有一些第三方模块不当使用了内存池,比如本该在请求内存池里分配内存,却在连接内存池分配内存,这可能会导致内存的延期释放,导致nginx的内存无谓的增加,这需要我们注意。
参考
陶辉老师的Nginx核心知识100讲